




CAPÍTULO I. EL MERCADO DE LOS DATOS
Vivimos en un período de emocionantes innovaciones y cambios. El World Economic Forum lo llama la web del mundo, dado que la comunicación, las nuevas tecnologías e internet interconectan a las personas en una misma red[1]. La accesibilidad a la información ha aumentado considerablemente, sobre todo gracias a la aparición de nuevos intermediarios, y se ha facilitado la transacción a través de las fronteras nacionales, tanto para individuos como para empresas. Este nuevo mundo, caracterizado por una profunda interconexión, ha visto surgir el desarrollo de una verdadera economía digital, con sus propias reglas, triunfadores y perdedores. Entre estos últimos encontramos empresas que no han querido, o podido, transformar su modelo de negocio de acuerdo con los cambios de la revolución tecnológica, mientras que, entre los ganadores, figuran las llamadas ‘plataformas digitales’. Esta expresión alude a compañías cuyo modelo de negocio permite a múltiples participantes conectarse con ellas, interactuar entre sí, y e intercambiar valor. La Comisión Europea las define como “todas aquellas empresas que cubren diferentes tipos de actividades como online marketplaces, social media, plataformas de distribución de aplicaciones, páginas web de comparación de precios, plataformas para la economía colaborativa, así como motores de búsqueda online”[2]. Es importante considerar también que determinadas plataformas digitales han ido adquiriendo más poder en sus mercados y, por tanto, más atención por parte de las autoridades y del debate público. Por consiguiente, aunque todas ellas puedan presentar características parecidas, el interés de este informe se centra sobre todo en algunas de ellas: las que han conseguido ganar más cuota de mercado y están teniendo un mayor impacto, ya sea en los beneficios o en los riesgos para la sociedad (capítulo 2).
Como veremos en el curso de este estudio, el núcleo del modelo de negocios de estas nuevas empresas consiste, sin duda, en la recopilación y gestión de ‘datos’, un término que engloba el conjunto de información procedente de los usuarios de estas plataformas: quiénes somos, nuestros intereses, nuestro pasado y, probablemente, pinceladas sobre nuestro futuro más cercano. Este inmenso flujo de datos ha creado nuevas infraestructuras, nuevos negocios y, fundamentalmente, nuevas economías, así como nuevos desafíos para la sociedad. Esta revolución promete originar un cambio radical, al que ya estamos, en parte, asistiendo en muchas industrias, por ejemplo en la sanidad y las finanzas[3]. Por todas estas razones, resulta de primordial importancia entender cómo funciona este mercado y la importancia de los datos de cara a que una empresa siga siendo competitiva.
Por ello, en esta introducción se presentarán algunas características fundamentales de las plataformas digitales, que explican tanto su funcionamiento general como los orígenes de su reciente éxito. Al mismo tiempo, esto permitirá comprender mejor sus problemas más relevantes (capítulos 2 y 3).
Para realizar esta semblanza, no puede dejar de considerarse el mecanismo del mercado de datos, base del modelo de negocio adoptado por las compañías cubiertas por el estudio. Una vez investigado este elemento, se abordarán las tres dimensiones que explican la clave para ganar en la economía digital. Son los rendimientos crecientes de escala, los efectos de red, y el ciclo virtuoso de los datos.
El mercado de los datos
Como se ha mencionado anteriormente, los datos personales se identifican con todo tipo de información que una persona física o una empresa deja en la red: sus movimientos, intereses, relaciones y rastros que, más o menos conscientemente, se introducen en internet. Así, se puede pensar en los datos de un usuario como si de su registro digital se tratase, en el que queda plasmada su evolución dentro de la web. Dentro de este registro, los datos evolucionan en función de la información que se provee a través de las plataformas digitales, y se almacenan en alguna base que forma parte de las identidades digitales de los usuarios. Sin embargo, no todos estos datos los producen o los facilitan ellos mismos. El World Economic Forum los categoriza, según su forma de adquisición, en tres grupos: voluntarios, observados y deducidos. Los voluntarios son los datos que la persona da directamente a la plataforma a cambio de recibir un servicio. Por ejemplo, los bancarios, cuando se compra un producto por internet, o los personales a la hora de suscribirse a una plataforma. Los observados se encuadran en el historial de movimientos que un individuo hace dentro de una plataforma online. Por ejemplo, las compras, o las preferencias que se pongan para recibir más servicios: la plataforma las observa y las adquiere, para poder ofrecer más prestaciones parecidas en el futuro. Por último, los deducidos no los proporcionan los individuos, sino que se consiguen a través de un análisis de los datos voluntarios e históricos. Son los que permiten a una empresa resultar más competitiva que las demás, porque, a través de ellos, estudia la información que recibe, y saca conclusiones ventajosas para su negocio. Por ejemplo, analizando datos voluntarios y observados, tiene la oportunidad de descubrir otros intereses que no están declarados específicamente. Cada tipo de estos datos personales (voluntarios, observados o inferidos) puede ser creado por múltiples fuentes (dispositivos, software, aplicaciones), almacenadas y agregadas por diversos proveedores (minoristas web, internet, motores de búsqueda, o empresas de servicios públicos) y evaluados para una amplia variedad de propósitos y muy diferentes usuarios (finales, empresas, organizaciones públicas)[4].Por eso, la delimitación entre los diversos tipos de datos no siempre es clara.
Esta sistematización abre la puerta a una ulterior consideración sobre la propiedad de los datos y su accesibilidad. Aunque, en su mayoría, los producen los usuarios (por ejemplo, por medio de publicaciones en redes sociales, correos electrónicos y mensajes instantáneos), la respuesta a la pregunta «de quién son y cuán realmente accesibles» parece menos obvia. Tras la aprobación por parte de Europa del Reglamento General de Protección de Datos (GDPR), que desglosaremos con más detalle en el capítulo 4, para los ciudadanos europeos está vigente hoy la posibilidad de solicitar sus datos, pero el proceso para obtenerlos ciertamente no destaca por su velocidad y simplicidad[5]. El hecho de que las plataformas digitales retengan los datos de sus usuarios, a menos que estos los pidan de manera explícita, no tiene en cuenta que, a partir de su acumulación y de una fácil lectura, los internautas podrían aumentar el conocimiento de sí mismos, y subestima el riesgo de fuga de información en caso de que los datos se pirateen o, simplemente, se vendan. Por otro lado, como veremos a lo largo del informe, las plataformas digitales se alimentan de la disponibilidad de datos para mejorar su posición en el mercado y llegar, incluso, al monopolio (en particular, a través del ‘efecto de red’ que se describe más adelante). Superar este riesgo, y asegurar que los beneficios de la competencia continúan redundando en el sector, implica repensar el concepto de derechos de propiedad de los datos, mediante la aplicación de reformas análogas a las que se han avanzado en el pasado en sectores como el de la telefonía móvil. De hecho, en esta última área, la mayoría de los países han establecido el derecho a la ‘portabilidad’, por el cual el número de teléfono pertenece al usuario y no a la compañía que lo suministra, lo que promueve la competencia entre las empresas y reduce los precios para el consumidor. Del mismo modo, varios autores están postulando la hipótesis de que los usuarios posean la propia red de relaciones digitales (‘social graph’) que han creado en una red social y que, por lo tanto, puedan transferirla fácilmente a una nueva plataforma sin perder su red de ‘amigos’[6].
Otra característica importante dentro del mercado de los datos hace que haya que plantearse las distintas maneras en que estos se pueden utilizar. La Comisión Europea define cuatro categorías de uso: uso no anónimo de datos individuales, uso anónimo de datos individuales, datos agregados y datos contextuales[7]:
- Con el uso no anónimo de datos individuales, se refiere al que se les da para ofrecer un servicio a un individuo. Por ejemplo, una empresa que vende productos online los utiliza para combinar mejor las preferencias de las personas con nuevos o diferentes productos que les podrían interesar.
- El uso anónimo de datos individuales sirve cuando con ellos se pretende mejorar un programa de machine learning[8].
- Los datos agregados se utilizan a nivel grupal, caso de los que ofrecen las instituciones públicas acerca de la población de un país.
- Los datos contextuales son aquellos externos a los individuos que se emplean para ofrecerles un mejor servicio: de localización, temperatura, lugares, etc.
Los diferentes tipos de datos y categorías de uso son conceptos necesarios para entrar en el debate sobre su protección y la privacidad, porque explican la heterogeneidad y la complejidad de este mercado. Además, hay otras características a tomar en cuenta cuando se habla de la economía digital, ya que aclaran por qué estos nuevos modelos competitivos no siempre resultan compatibles con los tradicionales. Así, muchos de los más innovadores mercados digitales derivados de internet, como los motores de búsqueda, las redes sociales o el e-commerce sufren de una altísima concentración, que los hace estar dominados por una o unas pocas empresas. En las siguientes páginas, describiremos las principales razones por las que estos mercados son distintos y, por tanto, necesitan de nuevas propuestas:
- Las plataformas digitales han logrado, gracias a los distintos tipos de datos, que los rendimientos de escala sean crecientes. Esto significa, por un lado, que el coste marginal disminuye conforme aumenta el número de usuarios y, por otro, que adquirir un nuevo dato resulta siempre positivo para la plataforma digital.
- Los efectos de red (network effects): La conveniencia de utilizar una tecnología o un servicio se incrementa con la cantidad de consumidores que lo adoptan. En consecuencia, no basta con que un nuevo participante ofrezca una mejor calidad y/o un precio más bajo que la empresa ‘incumbente’; la startup tendrá también que convencer a los usuarios del titular para coordinar la migración a sus propios servicios.
- El ciclo de la Inteligencia Artificial (IA): Con los avances de esta y de las nuevas tecnologías, las compañías pueden utilizar los datos en manera exponencial, creando un círculo virtuoso dentro de sus modelos de negocio.
1. Rendimientos de escala
La economía digital se trata ante todo de un mercado de información. Las plataformas digitales y todas las empresas que centran su modelo de negocio en los datos, en el fondo, los venden para mejorar un servicio o lanzar nuevos productos. Sin embargo, la teoría económica considera la información como un bien público, es decir, no rival y tampoco excluyente[9]. Esto quiere decir que no se puede vender como tal, dado que ofrecerlo a otro individuo o empresa no excluye que se pueda seguir utilizando. Si, junto a esta definición, se toma en consideración la actual monetización que las empresas digitales hacen a partir de estos datos, es fácil ver como la posesión de información solo puede tener efectos positivos para una compañía y, por tanto, implica unos rendimientos de escala crecientes. Por esto, aunque el coste inicial de conseguir datos sea alto, en cuanto se atiende a un usuario adicional, los costes no aumentan proporcionalmente. De hecho, una vez creado un bien digital, su coste de transmisión a otros individuos es prácticamente nulo.
Respecto a este punto, hay dos cuestiones que sirven como ejemplo para entender la fuerza de los rendimientos de escala crecientes dentro del modelo de negocio de las plataformas digitales. Por un lado, según datos de Facebook a fecha 31 de marzo 2019, esta red social tiene alrededor de 65.000 usuarios mensuales por cada trabajador[10]. Por otro, esta compañía puede permitirse gastar en torno al 1% de su valor anual en pagar a sus empleados, porque obtiene el resto de su trabajo de forma ‘gratuita’ por parte de los usuarios. En contraste, si se contempla una empresa con un modelo de negocio más tradicional, por ejemplo Walmart, esta destina el 40% de su valor a salarios[11]. Además, los rendimientos de escala crecientes crean barreras de entrada y, por ende, constituyen una restricción a la competencia. Así, las plataformas digitales, gracias a un número de clientes elevado y un coste promedio bajo, se hallan en disposición de ofrecer productos a bajo precio y de buena calidad; una que una nueva empresa no puede igualar sin acometer la misma operación a gran escala para pagar los costes fijos. Una start-up interesada en brindar un nuevo servicio solo logrará alcanzar una gran escala si la calidad es alta. Por consiguiente, un potencial participante no entrará en el mercado para desafiar a la compañía dominante.
La presencia de grandes economías de escala también ayuda a comprender el incremento de los servicios gratuitos. Las plataformas digitales han conseguido distribuir servicios ‘gratuitos’ a cambio de datos, ya que sus mayores ingresos derivan de la publicidad. Esta coincidencia de nuevas necesidades y de falta de conocimiento por parte del usuario acerca de las nuevas tecnologías han creado un tipo de economía de trueque entre plataforma y consumidor en el que los datos se intercambian por servicios. Por tanto, los datos se han convertido en un producto que, a su vez, se transforma en capital para las empresas, y que les permite utilizarlo como si fuera de su propiedad. En este informe, estudiamos una posible alternativa a este uso de los datos por parte de las plataformas digitales que cambiaría su modelo de negocio por completo y lo haría más eficiente.
2. Efectos Network
El segundo aspecto que diferencia este mercado de un modelo clásico es el ‘network effect’, es decir, la conveniencia de usar una plataforma está directamente relacionada con el número de usuarios que está en ella. Pensamos por ejemplo en Facebook o LinkedIn: su éxito reside en que muchos individuos estén conectados a través de la misma red. Como veremos en los siguientes capítulos, este efecto tiene doble impacto para la ´incumbente’: por un lado, es positivo porque hace más alta la barrera de entrada a posibles competidores; por otro, una vez que una compañía consigue entrar en el mercado y captar a muchos clientes, la empresa que la ha precedido se puede volver completamente obsoleta (i.e. MySpace, o MSN). Por ello, los mercados con efectos network se muestran propensos a la concentración: los consumidores se benefician de hallarse en la misma red que otros usuarios. Nadie quiere estar solo en su propia red social.
Un caso interesante dentro del network effect es el de las plataformas de múltiples lados, también conocidas como matchmakers, que agregan en una sola a distintos grupos con intereses complementarios, para que se intercambien bienes y servicios. El ejemplo más claro lo encontramos en Airbnb, que conecta a los propietarios de apartamentos con los inquilinos. Vale la pena señalar que este tipo de negocio se ha empleado mucho en los últimos años en el mundo de las fintechs para entrar en diferentes industrias y romper completamente sus modelos de negocio. Pensemos en el sistema de pagos, en los préstamos entre particulares (P2P Lending), o en el crowdfunding. Para todos estos sectores, existen plataformas digitales que han logrado unir a los consumidores con los oferentes, dejando de lado al intermediario.
También en este aspecto las plataformas encuentran una ventaja en no cobrar a los usuarios que desean entrar en su sistema, ya que saben que los datos que les proveen servirán para imputar un precio mayor a las empresas de publicidad y a las que quieren atraer más clientes. Así, los usuarios de Gmail pagan un precio monetario de cero, pero permiten que Google lea sus correos electrónicos para que los anunciantes puedan comercializarlos en función de su información personal. Google, en cambio, puede cobrar un alto precio por los anuncios.[12] Como en el caso de los rendimientos de escala, los efectos de red también hacen que resulte muy complicado para una nueva empresa entrar en un mercado donde haya ya una plataforma. La razón está en la dificultad para los usuarios de moverse en masa hacia la nueva, y en la falta de incentivos a nivel individual de cara a moverse desde una plataforma donde haya un grupo de interés a otra que se está formando. De este modo, los efectos de red podrían impedir que una nueva plataforma sustituya a otra antigua. Incluso, aun cuando no se puedan evitar, estos ‘efectos’ hacen que la transición sea más lenta y costosa para el nuevo líder del mercado de lo que podría haber sido[13]. Estas altas barreras de entrada debidas a los efectos de redes llevan a pensar que el mercado tal vez sea más eficiente cuando haya un monopolio. A partir de este supuesto, que discutiremos a lo largo del informe y frente al que propondremos una solución más satisfactoria en términos de libre competencia, algunos autores sugieren que la mejor manera de limitar estos monopolios consiste en una política de regulación, en vez de en crear un mercado más competitivo y abierto a otras empresas[14].
Esto resulta especialmente importante desde el momento en que el interés de las plataformas diverge del interés público. Las grandes plataformas sociales como Facebook, Twitter y Youtube están ocupando cada vez una posición más preeminente como intermediarios en el debate y en la formación de normas culturales[15]. Esto tiene relevantes efectos secundarios en la esfera social más allá del ámbito de las plataformas. Por lo tanto, no hay razón para esperar que estas gestionen la situación de manera eficiente: cuentan con un incentivo para usar su papel dominante y aumentar de este modo su influencia política[16].
3. El ciclo virtuoso de los datos
El último aspecto que merece la pena señalarse es cómo la evolución de la tecnología ha ido afectando al mercado de los datos. La idea de que la información sobre los usuarios sea el activo central para los gigantes de la tecnología se hizo cada vez más relevante con la explosión del big data, del machine learning y de la inteligencia artificial en los modelos de negocio de las empresas y en aspectos de nuestra vida cotidiana[17]. De hecho, como sugiere el informe de la Comisión Europea, los datos son uno de los ingredientes clave de la inteligencia artificial (IA), y un aporte crucial para los procesos de producción, de logística y del marketing dirigido. La capacidad de usarlos y de desarrollar aplicaciones y productos innovadores se trata de un parámetro competitivo cuya relevancia seguirá aumentando[18]. En muchos sentidos, la inversión en big data se ha movido hacia la inteligencia artificial, hasta convertirla en la fuerza impulsora detrás de la recolección de datos de muchas organizaciones y de los esfuerzos de monetizarlos, bajo la premisa de ofrecer mejores servicios y productos a los usuarios, a través de estas nuevas tecnologías. En el centro de la implementación de la IA se halla una de las técnicas del machine learning denominada supervised learning, que utiliza aquella para descubrir una relación de A a B. Por ejemplo, un sistema que determina si un correo electrónico es spam o no, o bien los objetos en una imagen. En otras palabras, asimila datos y genera un resultado. Esta información se puede presentar en formatos estructurados (hojas de cálculo) o no estructurados, como audio, vídeo y texto. Cuantos más datos tengan a su disposición, más potentes serán los algoritmos. Sin embargo, la tecnología que ha permitido a la IA crecer exponencialmente en los últimos años es el neural networks, o redes neuronales[19]. En los modelos tradicionales de machine learning, aunque creciera el volumen de los datos, las posibilidades de la IA resultaban limitadas. Ahora, gracias a estas redes neuronales, la barrera se ha roto y el rendimiento de la IA ya solo depende de dos aspectos: la cantidad de datos y la potencia computacional. Así, si se procesan más datos en mejores redes neuronales, la evolución de la IA será cada vez mejor. En el libro Radical Market, sus autores explican exhaustivamente el funcionamiento de estas neural networks. En lugar de que los inputs determinen de forma directa e independiente de los outputs, con las redes neuronales, los inputs se combinan en formas complejas para crear ‘características’ del fenómeno que se está estudiando, lo que a su vez condiciona otras, que acaban por hacer lo proio con el resultado[20]. Esto nos adentra en el último punto de la actual fuerza de los mercados de datos: el ciclo virtuoso de la IA.
Este empieza con una empresa que, a través de la creación de un producto, consigue usuarios, los cuales ofrecerán más datos al utilizar aquel. La adquisición de esta información por parte de la empresa, junto con la integración de las tecnologías de IA, permitirá crear o perfeccionar el producto para el consumidor, creando un circuito de retroalimentación por el cual el producto mejora continuamente con el uso, lo que hace que este se incremente, y obtenga una mejor posición competitiva en relación con otros. Este circuito virtuoso, unido a las redes neuronales, ha llevado a las plataformas digitales a jugar un papel cada vez más importante en el mercado e invertir más capital para conseguir más información de los usuarios. Así, los vastos conjuntos de datos recopilados por Google, Facebook y otros como un subproducto de sus funciones comerciales básicas se han convertido en una fuente crucial de ingresos y de ventaja competitiva. Las compañías que comenzaron como proveedores de servicios libres y que se transformaron en plataformas de publicidad ahora están en proceso de convertirse en recolectores de datos, por medio de servicios que atraen a los usuarios y les incitan a proveer información con la que desarrollan la IA a través del machine learning.
Profundizar en estas características permite identificar en la dimensión de los datos el componente principal del modelo de negocio de las empresas activas en la economía digital. A lo largo de este informe, trataremos de comprender qué problemas plantea esto y los desafíos que debe enfrentar nuestra sociedad para equilibrar los beneficios obtenidos con las amenazas relacionadas (capítulo 2). En particular, nos centrararemos en el tema de la privacidad y la protección de datos (capítulos 3 y 4), que cada vez están jugando un rol más importante en el debate acerca de las plataformas digitales. En el núcleo del problema hay una consideración simple: el modelo de negocio de estas compañías se basa en un incentivo continuo para capturar un número creciente de información sobre sus usuarios y ser lo más competitivas posible. La necesidad de acceder a nuevos datos y la facilidad con que estos se consiguen a menudo desmboca en la pregunta de si todavía tiene sentido hablar de privacidad[21]. Respecto a esta visión de un ‘final de la privacidad’, de la que luego se retractó parcialmente su propio autor[22], veremos más adelante cómo es más exacto hablar de una ‘paradoja de la privacidad’, según la cual cada vez más usuarios están preocupados por su privacidad, pero, a la vez, comparten también más información personal.
Abordar este problema, que considera que el respeto por la privacidad, entendido como un derecho humano universal (artículo 12), se entrelaza con la protección de datos, constituye un desafío que afecta a nuestra sociedad de manera interdisciplinar. Al tratar de contribuir a este debate, veremos que detrás de las soluciones propuestas, se esconden con frecuencia diversas concepciones filosóficas. Nuestro punto de vista a este respecto tomará los datos empíricos, donde estén disponibles, como un punto de partida. Se compararán con el patrimonio intelectual de la tradición liberal clásica, que ha hecho de la defensa de la privacidad un caballo de batalla. En este sentido, resultará interesante observar cómo, incluso si el respeto por el derecho a la privacidad se opone históricamente al control estatal, la preocupación actual se refiere más bien a su protección frente a la violación por parte de las empresas. Al ahondar en este aspecto, constataremos qué tipo de soluciones reglamentarias se están implementando (capítulo 4), especialmente a nivel europeo, para afirmar este derecho.
Finalmente, la regulación de la privacidad en la economía digital no puede sino formar parte de un enfoque más general respecto a las plataformas digitales, cuyas soluciones actualmente más en boga se desgranarán en el capítulo 5, y se cotejarán con las enseñanzas del liberalismo clásico en el 6.
CAPÍTULO II. LAS BIG TECH
En el primer capítulo, hemos introducido el mercado de datos y hemos analizado varias características que pueden estar relacionadas con su estructura de mercado y que pueden conducir a una falta de competencia entre empresas y a una situación de monopolio en diferentes industrias. En este capítulo, explicaremos las consecuencias que tiene el mercado de datos para el modelo de negocio de las plataformas digitales y cómo se irá desarrollando en el futuro.
Como anticipamos en el capítulo anterior, no es fácil encerrar en una sola definición los diferentes tipos de plataformas. Por ello, de aquí en adelante, las definiremos como aquellas empresas tecnológicas que compartan la integración en su línea de negocio de una plataforma abierta en la que los usuarios intercambien bienes y servicios, y que vendan los suyos propios[23]. Esta característica en concreto ha llevado a muchos políticos, académicos e intelectuales a cuestionar el éxito de estas plataformas y a compararlas con otras industrias o sectores que han devenido en casos de oligopolio a lo largo del tiempo[24]. Está claro que cualquier compañía que tenga la posibilidad de gestionar una plataforma y de vender sus productos en ella acabará obteniendo beneficios, lo que aumentará cada vez más su poder de mercado frente a los demás participantes. Las empresas que más éxito han cosechado en este aspecto son las GAFAs: Google, Amazon, Facebook and Apple (ver BOX I). Cada una de ellas ha logrado unir las dos líneas de negocio que acabamos de mencionar y crear una posición dominante dentro de sus plataformas[25]. En este capítulo, trataremos dos temas relacionados con las GAFAs. Por un lado, algunas de las estrategias que utilizan para conseguir más poder y ofrecer mejores servicios (la publicidad digital (‘digital advertising’) y la inteligencia artificial). Por otro, las amenazas que estas mismas empresas generan para nuestra sociedad.
Digital Advertising
Uno de los aspectos que más réditos arroja para estas plataformas es el ‘digital advertising’, es decir, el saber dirigir las ofertas y productos a los usuarios que pueden estar interesados. Facebook y Alphabet (el holding de Google) obtienen más del 90% de sus ingresos gracias a la publicidad digital[26], y controlan más del 60% de este sector[27]. Sin embargo, este no se limita a ambas plataformas. En los últimos años, Amazon y otras han aumentado su inversión en publicidad para mejorar sus servicios, y llegar con más facilidad a potenciales clientes. Por ejemplo, Amazon puede conocer la última vez que una persona ha comprado un determinado producto y cuál es su marca favorita. Los anunciantes son susceptibles de utilizar esta información para encontrar el mejor target y saber cuándo un potencial cliente necesita un determinado bien[28], con más eficiencia y menos costes. Tomemos como ejemplo un fabricante de gafas de sol. Antes de que existiera la publicidad digital, esta empresa necesitaba pensar en qué revistas y canales de televisión insertaba su publicidad para atraer más consumidores. Esta estrategia resultaba muy cara y poco eficiente, porque no permitía controlar con exactitud qué personas veían esa revista o canal justo en el momento en que aparecía el anuncio. Hoy en día, gracias a la publicidad digital, tanto impactar al cliente interesado como programar la publicidad en determinados momentos resulta más fácil. Siguiendo con nuestro ejemplo, el fabricante de gafas sabrá si la persona está buscando otras gafas de sol, ropa de verano, o si ha salido un día soleado. Toda esta información pueden recogerla las plataformas digitales como Amazon, Google y Facebook, proporcionársela a las diferentes empresas, y así facilitar su búsqueda[29]. A su vez, los servicios de publicidad ofrecidos por estas plataformas a las compañías han posibilitado que las primeras aumenten su número de usuarios (a través del network effect) y conocer los mejores productos y servicios de las segundas.
Antes de describir las consecuencias que la publicidad digital ha entrañado para la economía digital es importante entrar con un mayor detalle en el funcionamiento de esta estrategia. A continuación, explicamos diferentes modelos relacionados con la publicidad digital, utilizando como punto de referencia los dos que han reportado más éxito: Google AdWords y Facebook Ads, los respectivos departamentos responsables de las publicidades de Google y Facebook.
Google AdWords sigue principalmente un sistema de ‘pay-per-click’ (PPC). Es decir, Google cobra a los anunciantes cada vez que un usuario pincha en su publicidad. La aparición de esta a través de AdWords depende de dos factores. Primero, de que las palabras clave de la búsqueda coincidan con las que los anunciantes han asociado a la suya. En segundo lugar, del ‘Ad Rank’ de la empresa respeto a sus competidoras. Este ranking de compañías está sujeto a su vez a dos elementos: el precio que los anunciantes están dispuestos a pagar por cada clic (siguiendo un sistema de pujas) y la calidad de los anuncios[30]. Estas dos métricas se multiplican entre sí, y el anunciante que obtenga el número más alto será el que primero aparezca en los resultados de búsqueda pagados. ‘The Quality Score’ depende de varios parámetros que permiten a los anunciantes pagar menos:
- El Click-Through Rate (CTR) del anuncio, o lo que es lo mismo, el porcentaje de clic que este genera respecto al número de impresiones, consideradas estas como las veces que un anuncio se muestra en pantalla por primera vez[31]. Si el anuncio PPC tiene 1.000 impresiones y 1 clic, equivale a un CTR de 0,1%. Como métrica, el CTR indica cuán relevantes son los buscadores para encontrar el anuncio. Por tanto, y aunque por regla general un CTR alto es mejor, hay que tener en cuenta la eficiencia de los anuncios. Un CTR bajo estará bien siempre que las palabras clave y anuncios se desempeñen correctamente en función de los objetivos comerciales.
- La relevancia de las palabras clave que activan el anuncio respecto a la búsqueda del usuario. Por ejemplo, ofrecer un producto gratuito en el anuncio solo para que los usuarios entren en la página web hará que el ‘quality score’ tenga una puntuación menor.
- La calidad de la página web, ya que, cuanto más relevante sea la página de destino respecto al anuncio, mayores posibilidades habrá de obtener un buen ‘quality score’.
Este sistema permite que no sea el anunciante que pague más el que logre mayor visibilidad. La calidad del servicio y la experiencia del usuario constituyen elementos fundamentales para que la publicidad recabe óptimos resultados. De hecho, cuanto más calidad tenga, menor será el precio que el anunciante pague[32].
Otro método utilizado por las plataformas, aparte del PPC, es el ‘Cost-per-mille’ (CPM), que denota el precio de 1.000 impresiones publicitarias en una página web. Los anuncios de Facebook presentan un costo promedio por clic (CPC) de 1,86 dólares, y uno por cada mil visitas (CPM) de 11,2 dólares, el cual varía en función de factores que van desde la calidad del anuncio hasta la competencia. Sin embargo, la verdadera fortaleza de la inmensa audiencia de Facebook radica en la granularidad con la que los anunciantes pueden dirigirse a los usuarios. Entre los modelos más utilizados en Facebook Ads figura el ‘lookalike audience’, una herramienta gracias a la que plataforma encuentra potenciales clientes basándose en los clientes pasados. Por ejemplo, un vendedor de libros que conoce su target puede ofrecer esta base de datos a Facebook, que le puede ayudar, a su vez, a hallar posibles clientes que comparten la misma información. Este tipo de publicidad ostenta un peso importante en una plataforma como Facebook, donde los usuarios comparten datos personales y privados con los demás miembros de la red social. Así, esta se trata de la plataforma con más información sobre intereses y relaciones. Eso sí, para que la publicidad dé sus frutos, es importante disponer de una base de datos de gran calidad. Si bien puede existir una mayor inclinación a maximizar el tamaño de las imitaciones, hay que tener en cuenta que las audiencias más pequeñas a menudo funcionan mejor, ya que, al fin y al cabo, son las que coinciden más con su fuente. Facebook recomienda usar una base de datos inicial de entre 1.000 y 50.000 personas para crear audiencias similares[33].
En conclusión, podemos apreciar cómo, a través de la publicidad digital, las plataformas no solo han encontrado uno modo de monetizar su negocio, sino también aumentar la cantidad de información personal de sus usuarios. La industria de los datos define el target advertising como una situación de ‘win-win-win’, en la que ganan los consumidores, los anunciantes y las plataformas. Es un bien para los consumidores, que ven una reducción en el coste de búsqueda de los productos; para los anunciantes, porque pueden hallar potenciales clientes más fácilmente; y para los intermediarios de datos, las plataformas, que captan dinero con estas transacciones[34]. A pesar de esto, un problema que queda sin resolver es el de la privacidad de los consumidores: el verdadero precio a pagar para beneficiarse de este sistema. Además, la situación de ‘win-win-win’ propuesta por la industria tecnológica no contempla la falta de transparencia en la publicidad de las empresas en Facebook[35].
El segundo elemento que crea preocupación en la opinión pública radica en el uso por las plataformas digitales de los avances de la IA para transformar sus negocios y entrar en nuevas industrias. Muchas de ellas han adoptado el machine learning y lo han integrado en su cultura corporativa. Como vimos en el capítulo 1, para estas empresas la IA no representa solo otra herramienta, sino la fuerza impulsora de su modelo de negocio. Esta filosofía las distingue de casi todos los demás, otros gigantes tecnológicos inclusive, porque pueden usar aquella para analizar una biblioteca de datos digitales y obtener información valiosa sobre cualquier industria en la que elijan penetrar[36]. Educación[37], viajes, sanidad[38] y muchas más están siendo completamente revolucionadas por las plataformas digitales. En este informe vamos a analizar una de las que, hoy en día, está viéndose más afectada por estas compañías y por la IA en general: las finanzas.
Según el Bank for International Settlements (BIS), en el último año, los servicios financieros han supuesto casi el 11% de los ingresos de las Big Tech[39]. Aunque, gran parte de este sector se concentra en China y en otros países en vía de desarrollo, las plataformas digitales están aprovechando los altos costes del sistema bancario en Europa y Estados Unidos para entrar también en estos mercados. El World Economic Forum ha analizado las áreas financieras más afectadas por parte de las nuevas tecnologías: los préstamos y depósitos, los seguros, los sistemas de pagos, las inversiones, el mercado de capitales y las infraestructuras de mercado[40]. Aquí se estudiarán solamente los sectores que han visto a las plataformas digitales protagonizar este cambio, es decir, los sistemas de pagos y préstamos[41].
1. Servicios de pagos
Fue el primer servicio que las Big Techs introdujeron en sus modelos de negocio para superar la falta de confianza entre consumidores y vendedores[42], agilizar la compra de productos en sus plataformas y mejorar su utilización. De hecho, el aumento del IA ha implicado muchos cambios en el sistema de pagos, como el mayor uso de interfaces móviles para hacerlos más rápidos en contraste con el efectivo. Asimismo, ha ayudado a reducir el fraude[43]. Las principales plataformas digitales han aprovechado los avances tecnológicos y el círculo virtuoso de los datos para ofrecer sus propios sistemas de pagos. El modelo más sencillo es el de las aplicaciones como ApplePay y GooglePay, en virtud de las cuales los usuarios confían en las infraestructuras de terceros (tarjetas de crédito o sistemas de pago minoristas) para procesar y liquidar pagos. Un modelo más avanzado lo encarna AmazonGo, una tienda sin cajero que rastrea lo que los visitantes han puesto en su carrito y lo cobra automáticamente usando sus métodos de pago preferidos cuando salen de la tienda. Detrás de este sistema hay un esfuerzo notable en reconocimiento de objetos y de machine learning[44]. La última plataforma digital que merece la pena citar es Facebook, que quiere dar un paso aún más adelante creando una moneda virtual propia, la Libra. Su misión es muy ambiciosa: ofrecer un servicio de pagos a todas aquellas personas que no tienen una cuenta bancaria, es decir aproximadamente 1,7 millones de personas[45]. La idea pasa por imitar el modelo de WeChat en China[46], que ha conseguido unir diferentes negocios en una misma app y ponerse en el centro de la vida de las personas. El modelo de la Libra se compone de tres partes que funcionarán de manera coordinada para generar un sistema financiero más inclusivo:
- Se basa en una tecnología blockchain[47]segura, escalable y confiable.
- Cuenta con el respaldo de una reserva de activos diseñada para aportarle valor intrínseco.
- Se rige por el gobierno de la Asociación Libra, de carácter independiente, cuya misión radica en la evolución del ecosistema.[48]
Hasta el momento, 28 empresas, incluidas compañías de pagos, grupos de comercio electrónico y empresas de capital de riesgo, han desvelado que se convertirán en patrocinadores e integrarán esta tecnología en sus servicios[49]. El plan consiste en crear una nueva fundación sin ánimo de lucro con sede en Suiza, compuesta por 100 miembros del sector privado y de la sociedad civil con los mismos derechos de voto, para lanzar Libra en la primera mitad de 2020[50]. Libra encierra el potencial de llevar a toda una generación a un sistema financiero más formal que, a largo plazo, pueda ayudar a las personas a construir su crédito y ascender en la escala socioeconómica.
Si, por un lado, parece que el futuro de las monedas virtuales se perfila como cada vez más cercano y evidente frente a la utilización del efectivo y como un medio por el que más personas puedan entrar en el sistema financiero, por el otro, las autoridades de regulación y las instituciones públicas no han dejado de observar los riesgos que estas monedas pueden entrañar para el sistema financiero global y para la privacidad de las personas. El 2 de agosto de 2019, las autoridades de protección de datos de EE.UU., UE, Reino Unido, Australia y Canadá publicaron una declaración conjunta en la que expresaban su preocupación por las amenazas que revestían estos planes de Facebook y alertaban de que la Libra “puede convertirse instantáneamente en el custodio de la información personal de millones de personas”[51]. También pedían que se creen configuraciones predeterminadas de protección de la privacidad y que no se empleen los llamados «patrones oscuros», técnicas que alientan a las personas a compartir datos personales con terceros[52]. El segundo aspecto de inquietud se refería al sistema financiero global. Por un lado, Libra dejaría demasiado poder en manos de un grupo autoseleccionado de grandes empresas; por el otro, plantearía riesgos sistémicos más profundos, al interferir con la capacidad de los bancos centrales de vigilar sus sistemas financieros y operar una política monetaria normal[53].
Todos los modelos avanzados por estas plataformas representan un adelanto para nuestra sociedad y, sin ninguna duda, llevan aparejadas muchas ventajas para los negocios y las personas. Sin embargo, a través de estos nuevos servicios, las Big Techs pueden conseguir más datos personales y, por tanto, un mayor poder sobre nuestras vidas.
2. Préstamos y depósito
El segundo mercado en el que las plataformas tendrían un gran impacto económico es el de los préstamos. Como reporta el World Economic Forum, la IA será (es) un completa revolución. Los productos de préstamo se volverán cada vez más pequeños y ágiles a medida que se personalicen para usos específicos. La gama de clientes potenciales aumentará conforme los datos no tradicionales permitan atender a nuevos consumidores y operar en nuevas regiones. Por tanto, las plataformas digitales cuentan con la ventaja respecto a los bancos de personalizar el tipo de empréstitos de dos maneras: ofreciendo productos propios gracias a los datos personales de sus usuarios, y creando una plataforma de matchmaking para prestamistas y prestatarios. Además, con las nuevas reglas europeas del ‘Open Banking’[54] y del PSD2[55], les resultará más fácil conocer los datos bancarios de sus usuarios y, por tanto, ofrecer productos a quienes no se pueden permitir un crédito bancario.
Amazon ha abierto un sistema de préstamos a pequeñas y medianas empresas en Reino Unido y EE.UU. Aunque los números no alcancen la dimensión de los del e-commerce, el gigante americano está invirtiendo mucho dinero en este sector y espera crecer en los próximos años. Ebay, competidora de Amazon, también ha decidido entrar en este mercado a través de una colaboración con el Banco Santander. La nueva empresa, Asto, brindará préstamos a finales de este año[56] a las más de 200.000 pymes que venden productos a través de eBay en el Reino Unido. El objetivo principal del banco español pasa por competir con los gigantes tecnológicos y las Fintech, utilizando sus mismas estrategias: muchos datos de usuarios y flexibilidad dentro de la empresa a la hora de bajar los costes.
El camino de las Big Techs en el mercado de préstamos es todavía largo, dado que las plataformas aún no poseen muchos datos bancarios de sus usuarios. Sin embargo, la colaboración entre Ebay y Santander puede erigirse en un buen ejemplo de cómo los bancos y las plataformas pueden unirse para ganar en dimensión y eficiencia.
En este capítulo, hemos analizado diferentes negocios que las plataformas digitales han desarrollado a lo largo del tiempo. Posner y Weyl en Radical Market hablan de estas como “empresas que comenzaron como proveedores de servicios gratuitos en busca de un modelo de ingresos y se transformaron en plataformas de publicidad, y ahora están en el proceso de convertirse en recolectores de datos, ofreciendo servicios que atraen a los usuarios y les incitan a proporcionar información sobre la cual entrenan a la inteligencia artificial usando machine learning”[57]. Aquí añadimos un aspecto más a este proceso vital de las plataformas digitales: su capacidad de entrar en nuevos mercados gracias a los círculos virtuosos de la IA y a la enorme cantidad de datos que pueden procesar gratuitamente. En esta publicación, hemos presentado solo dos de los mercados en los que las plataformas digitales están interesadas. Sin embargo, hay muchas más industrias donde pueden entrar y convertirse en líderes.
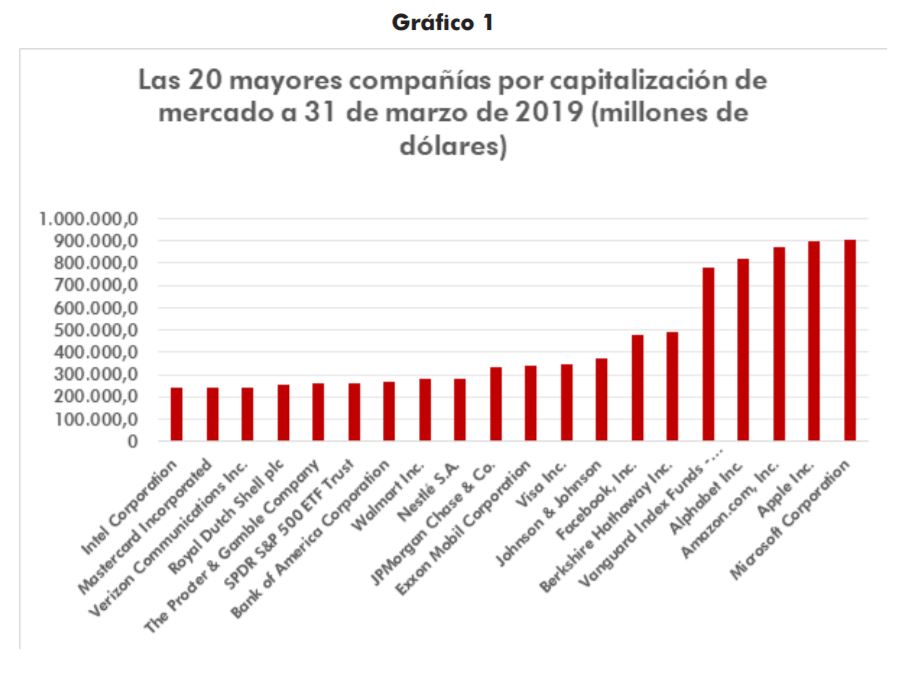
Muchas de estas plataformas han conseguido en solo 15 años erigirse en las empresas dominantes del mercado. Como se puede ver en la Figura 1, la capitalización de las GAFAs se halla hoy en día entre las mayores del mundo. Todas ellas juegan un papel muy importante en la sociedad actual: han sido las más innovadoras de los últimos años, al crear productos y servicios con un alcance global. Por eso, muchos gobiernos e instituciones han empezado a discutir sobre los riesgos que pueden encerrar estas plataformas, que son, ante todo, empresas privadas en busca de su propio beneficio. En este informe vamos a introducir brevemente diferentes aspectos que preocupan a la sociedad, para centrarnos luego en el punto principal de nuestra publicación: la privacidad y la protección de los datos personales.
El primer peligro que merece la pena tratarse y que ya hemos mencionado varias veces es el riesgo de monopolio que estas empresas presentan en sus respectivas industrias. En los últimos años, políticos y académicos han debatido sobre la posible existencia de una concentración de poder en las plataformas digitales y cómo esta pueda afectar a la competencia, la innovación y la estructura de mercado. Para explicar esta dinámica sirve el caso de Google.
Otro peligro relacionado con las plataformas digitales y su estructura de mercado se refiere a la democracia y los efectos en política. El caso de Cambridge Analytica (ver BOX II) basta para entender las perniciosas consecuencias que estas plataformas pueden originar en una sociedad democrática.
Por último, la privacidad: en los últimos tiempos, resulta cada vez más común encontrar noticias sobre algún escándalo relacionado ella, ya sea la ruptura de los cables de seguridad que defienden la información personal confidencial, o la revisión de las políticas de privacidad por parte de plataformas digitales que no cumplen las promesas precedentes sobre la defensa de sus usuarios.
Este tipo de noticias, cuando son difundidas por los medios de comunicación, generan un sentimiento generalizado de pánico, que deriva en la voluntad de retirarse de la plataforma objeto de la polémica o, en el mejor de los casos, en una creciente desconfianza hacia el sistema. Un coste muy importante en una sociedad interconectada como la nuestra, que abre el debate sobre qué hacer para resolver el problema. Uno que requiere equilibrar el incentivo de las empresas para recopilar una cantidad cada vez mayor de datos de los usuarios, con el fin de ofrecer servicios más personalizados y ganar participación en el mercado, y el derecho a la privacidad que, hoy en día, abarca hasta la protección de datos de los usuarios. Por tanto, hay que buscar soluciones que superen la dicotomía entre las solas fuerzas del mercado, o solo la regulación. La primera opción, como veremos, presenta el peligro de la ineficacia a la hora de lograr un resultado óptimo. La segunda, el de cargar a las pequeñas y medianas empresas que operan en el sector de la plataforma digital con un peso de compliance difícil de soportar y que, por ello, se traduciría indirectamente en una ventaja adicional para las empresas incumbentes y su creciente posición de monopolio.
El problema de la manipulación de la privacidad reviste una importancia primordial, no solo porque llega a tener consecuencias en nuestras instituciones más importantes (ver BOX II en Cambridge Analytica), sino porque amenaza con socavar un pilar fundamental de la sociedad: el de la confianza.
CAPÍTULO III. LA PRIVACIDAD
¿Puede existir la privacidad en la era digital? En un mundo hiperconectado, donde las personas están ocupadas interactuando entre sí a diario a través de alguna plataforma digital, ¿resulta posible hablar de un derecho a la privacidad? El hecho mismo de que se formule esta pregunta subraya la profunda transformación respecto al contexto cultural en el que se elaboró la Declaración Universal de Derechos Humanos. El artículo 12 establece lo siguiente:
“Ninguna persona puede ser objeto de interferencias arbitrarias en su vida privada, en su familia, en su casa, en su correspondencia, ni dañar su honor y reputación. Toda persona tiene derecho a ser protegida por la ley contra tales interferencias o lesiones”.
Con estas palabras se quería reafirmar el derecho de toda persona a mantener el control sobre su información: un requisito previo real para el ejercicio de otras libertades. Para ello, el Estado, o cualquier otro sujeto, tenía que abstenerse de interferir arbitraria o ilegalmente en la vida de las personas. A partir de este texto es posible entender que la privacy constituye un derecho difícil de respetar, porque se refiere a una esfera particularmente íntima de la persona y porque, constantemente, ha de lidiar con una tecnología y una necesidad creciente de seguridad, tanto a nivel nacional como internacional.
El desarrollo tecnológico que hemos presenciado en las últimas décadas ha requerido una nueva elaboración del derecho a la privacidad, que se ha ido extendiendo gradualmente hasta el tipo de acceso a la información personal que compartimos al utilizar los servicios digitales, a la protección de los datos contenidos en el mismo, y al control que los usuarios tienen de sus datos.
Vuelven todavía más compleja esta situación, ya de por sí difícil, las heterogéneas actitudes con que los consumidores se ocupan del problema de la privacidad online: divididos entre los que consideran la confidencialidad, a diferentes niveles, algo indispensable, y los que están dispuestos a renunciar a ella para obtener servicios a cambio; un hecho que no se puede olvidar a la hora de diseñar la regulación, y que desaconseja una solución única. La incapacidad de recoger en una sola propuesta esta diversidad de opinión de los usuarios ha sido una fuente de enorme interés para las plataformas digitales, que han cosechado considerables beneficios jugando precisamente con el cambio cultural de los consumidores.
El caso Facebook
Un caso paradigmático lo ofrece Facebook. Desde su fundación en 2003, la popular plataforma ha alternado declaraciones sobre la importancia del respeto a la privacidad con reformas encaminadas a lograr una mayor difusión de la información[58].
En el momento del lanzamiento de esta red social, la privacidad presentaba tal importancia que Facebook creó una línea de especial atención sobre el tema. Un enfoque que recompensaron los consumidores, muchos de los cuales eligieron esta plataforma sobre otros competidores en virtud de esta mejor gestión de la confidencialidad. Ante la existencia de otras redes sociales ya gratuitas como MySpace, Facebook se dio cuenta de la necesidad de una ventaja competitiva para diferenciarse, y lo hicieron respondiendo a la preocupación por la privacidad[59].
Esta estrategia llevó a la empresa a restringir el acceso a aquellos usuarios que podían validar su identidad con una dirección de correo electrónico establecida por una universidad (“.edu”), y las configuraciones por defecto (de default) se diseñaron para que los suscriptores solo pudieran ver el perfil de los colegas universitarios. Contra esto, MySpace tenía opciones predeterminadas más abiertas, y todos los usuarios podían ver las cuentas de los demás[60]. Lo que a primera vista parece un simple detalle, se trata de un elemento que contribuye a la calidad de un producto porque, como demuestra una amplia investigación científica, los consumidores se muestran reacios a cambiar la configuración por defecto, razón por la que la elección de la empresa se convierte para muchos usuarios en la definitiva[61]. Un compromiso adicional respecto al cumplimiento de la privacidad era que Facebook no utilizaría una tecnología como las cookies. Estas—códigos cortos que las plataformas digitales pueden instalar en los ordenadores a través de las URL de sus páginas web— permiten que un sitio recuerde las acciones de un usuario (comprar un producto, iniciar sesión en un sitio) que tuvieron lugar a través de un navegador, a fin de mejorar la calidad de su experiencia en la página web. Al ser también utilizadas para determinar lo que el usuario está buscando, leyendo, o comprando, las cookies constituyen una especie de huella que el internauta deja en la página web visitada, y que puede emplear la empresa propietaria del sitio para rastrear los detalles (ubicación geográfica, hora de visita, dirección IP, ID de cookie) de esa visita. Dos características limitan el uso de cookies por parte de las compañías. La primera, que una empresa solo puede leer sus propias cookies; la segunda, que solo podrá leerlas cuando el usuario inicie una búsqueda en el servidor de su sitio web (la información que puede obtener sobre el usuario se relaciona con lo que es en su sitio web y no en otros)[62].
Por otro lado, es posible que una empresa eluda estas protecciones de privacidad instalando su propio código en la página web de otra compañía, lo que, por supuesto, esta última nunca permitiría (se trata de una simple demostración de cómo la competencia entre empresas se traduce en una mejor privacidad para el usuario). La situación cambia cuando una plataforma como Facebook se convierte en intermediario en la navegación online (por ejemplo, a través de búsquedas en sitios web que se inician a través de la cuenta de Facebook). Esto genera algunas complicaciones a nivel de protección de datos. La primera, que Facebook asocia un determinado ID de cookie con la verdadera identidad de los usuarios, por lo que la búsqueda en una web ya no se corresponderá con un código anónimo, vinculado al ordenador del usuario, sino con la cuenta específica de la red social. La segunda complicación radica en que, de esta manera, Facebook puede recopilar información mucho más integral sobre los gustos y preferencias de los usuarios[63]. Para paliar la preocupación suscitada, Facebook aseguró inicialmente que no controlaba el comportamiento de los usuarios fuera de la plataforma, y también que daba a estos la posibilidad de rechazar la divulgación de su propia información a terceros, así como prohibir que Facebook recopilara información sobre ellos de parte de terceros. Presentarse como una red social ‘cerrada’, con estrictas opciones de privacidad predeterminadas, favoreció que los consumidores la eligieran, lo que dio a Facebook una posición que, a partir de 2014, podría considerarse como de monopolio, según han subrayado varias fuentes citadas en este informe. Una vez asumido este control, Facebook no tardó en comenzar a revisar sus políticas de privacidad, especialmente las relativas a la posibilidad de llevar a cabo operaciones de vigilancia de los usuarios con fines comerciales, utilizando así un esquema tecnológico construido a lo largo de los años, precisamente bajo la promesa de que no lo emplearía con este propósito. Por lo tanto, esa posición de fuerte dominio en el mercado se erigió sobre unos compromisos que se modificaron a posteriori para poder capitalizar aquella. Estos cambios sobre la privacidad no han pasado desapercibidos. Especialmente grave fue el escándalo de Cambridge Analytica (véase BOX II), hasta el punto de que condujo a una nueva reflexión sobre el tema.
Anonimato y control
El caso de Facebook podría sugerir que los problemas de privacidad surgen cuando los usuarios proporcionan información particularmente confidencial (nombre, apellido, dirección). Sin embargo, estudios recientes han demostrado que incluso la “anónima” permite a las plataformas digitales reconstruir la identidad personal. Un ejemplo notable en este sentido lo encontramos en Netflix, una compañía que opera en la distribución y producción a través de Internet de películas, series de televisión y otros servicios de entretenimiento. En 2009, fue acusada de violar el anonimato de algunos usuarios que habían calificado películas y series de televisión registrándose solo con su número ID[64]. Esto sacó a la palestra un problema ya conocido en el mundo de los científicos de la computación: incluso en bases de datos anónimos, donde se eliminan los más sensibles, es suficiente una información inofensiva pero idiosincrática para ser identificado. Se logra a través de un proceso que consiste en cruzar diferentes conjuntos de datos que se combinan con precisión para restringir el campo de identificación del usuario individual[65]. En el mejor de los casos, se pueden usar para políticas publicitarias específicas. El peligro estriba en que los compradores pueden vender los mismos datos, y luego emplearlos para inferir comportamientos futuros que pueden conducir, por ejemplo, a la denegación de una solicitud de crédito o de un trabajo[66].
En general, la preocupación de los usuarios sobre la utilización de sus datos parece aumentar a medida que perciben tener menor control sobre ellos. Recientemente, otros tres gigantes tecnológicos, Google, Apple Inc. y Amazon.com Inc., han sido criticados por hacer que sus empleados escuchen las grabaciones de comandos de voz dirigidos a asistentes digitales como Google Assistant, Siri o Alexa (en el momento de escribir este informe, los reguladores estadounidenses y europeos están investigando posibles violaciones de privacidad). A pesar de una justificación inicial por parte de estas compañías, que alegaban que su pretensión era mejorar aún más el servicio prestado, Google y Apple han suspendido el programa, mientras que Amazon ha anunciado que va a cambiar las condiciones de uso del dispositivo, habilitando la opción de no participar en el servicio de registro (opt-out)[67]. Respecto a este último punto, el nivel de preocupación sigue siendo, sin embargo, elevado. Como muestran algunos informes, la capacidad de los usuarios para sustraerse de este tipo de grabación se ve mermada por la falta de conocimiento sobre su existencia y las opciones que garantizan que el usuario ha consentido el servicio en cuestión[68]. Esto último está vinculado a otro asunto de gran importancia para la privacidad los patrones oscuros, dark patterns. Este término se refiere a unas interfaces gráficas que pueden confundir a los usuarios, dificultando que expresen sus preferencias actuales, o incluso manipularlos y llevarlos a realizar ciertas acciones.
Un ejemplo clásico de un dark pattern es una página web que ofrece la oportunidad de suscribirse a su boletín de noticias, presentando la ventana ‘acepto’ de una manera mucho más fácil de encontrar que la ventana de ‘No, gracias’. En los peores casos, se trata de sitios web diseñados de tal manera que sugieran que, para seguir navegando, es necesario suscribirse al boletín informativo. Ejemplos más agresivos pueden incluir la compra en páginas web que colocan en la ‘cesta’ virtual productos no seleccionados por el usuario, los cuales este tendrá que eliminar pacientemente para evitar adquirirlos. Algunos estudios han demostrado la proliferación de estos caminos engañosos entre los sitios web de compras más populares[69]. La pertinencia de contemplar los patrones oscuros a efectos de este estudio viene de que el proceso que lleva a los usuarios a tomar una determinada decisión afecta enormemente a la cantidad de datos recogidos.
Paradoja de la privacidad y datos empíricos
A esta idea de dar incentivos, en forma de servicios, para que los consumidores de las plataformas digitales publiquen cada vez más datos, la literatura la ha definido como la “paradoja de la privacidad”. Si bien los usuarios reconocen estar preocupados por la difusión de su información, son cada vez más los que comparten sus datos. Para tratar de entender las razones de esta paradoja, resulta útil reanudar algún análisis empírico, y así comparar el tipo de conocimiento que los usuarios tienen con el uso de los propios datos por parte las empresas. Esta información resulta a su vez relevante para medir la voluntad real con que los consumidores difunden su información. Si, de hecho, es cierto que ningún usuario está realmente “obligado” a compartirla, conviene saber el grado de conocimiento sobre las consecuencias de este intercambio. Una voluntad marcada por la ignorancia difícilmente puede considerarse libre.
Por lo tanto, para nuestros propósitos, es útil comprender las percepciones de los consumidores. Para ello, citamos aquí los datos recopilados por el Centro de Investigación Pew, para los ciudadanos estadounidenses, y los del Eurobarómetro para los de la UE. En cuanto a los primeros, refiriéndose a una investigación de 2018, parece que alrededor del 74% de los usuarios de Facebook de EE.UU. no eran conscientes del hecho de que la plataforma digital clasificaba sus intereses (una estrategia necesaria para el ‘target advising’, según lo analizado en el capítulo 2 de este informe) hasta que no fueron dirigidos a la página “your ad preferences” para realizar la encuesta. Una vez tuvieron acceso a esta sección, el 27% de los encuestados aseveraron que no se sentían representados por las listas producidas por los algoritmos, en comparación con el 59% que, en cambio, confirmó la coherencia entre las categorías y sus intereses reales. En cualquier caso, el 51% reportó cierta incomodidad al enterarse de que Facebook había creado esa lista. Una segunda encuesta, que extendió la muestra a los usuarios, no solo de Facebook, sino también de Twitter e Instagram, reveló que estos son conscientes de que sería relativamente fácil para las plataformas utilizadas rastrear sus hábitos en función de los datos recabados. Por otro lado, el funcionamiento preciso de los algoritmos para producir estos análisis sigue resultando casi desconocido para las personas ajenas a las empresas propietarias, así como el proceso de orientación a través del que las compañías de terceros utilizan el material recogido por Facebook[70]. De los resultados de esta encuesta se deduce que más del 70% de la muestra entrevistada permanece ignorante de la categorización de sus intereses por parte de las plataformas digitales y que, una vez descubierta, más de la mitad no se siente cómoda con ello.
Por lo que se refiere a Europa, partimos de un informe publicado por el Eurobarómetro sobre la protección de datos, resultado de una encuesta a los ciudadanos de los 28 Estados miembros de la UE en 2015 (antes de la entrada en vigor del Reglamento General de Protección de Datos (RGPD))[71].
Según este, el 31% de los consultados piensa que no tiene control sobre la información que se proporciona online. La inquietud no nace simplemente de la recopilación de estos datos por parte de empresas privadas, sino también de los gobiernos. En cuanto a la concienciación de los usuarios sobre la recolección de sus datos y su utilización por las plataformas, solo la mitad respondieron que siempre estaban al corriente de los métodos de obtención de datos y sus usos potenciales cuando se solicita información privada. Del mismo modo, solo el 20% de los encuestados dice que leyó sus declaraciones de privacidad online en su totalidad antes de dar el consentimiento; la mayoría de los que admitieron que no las leyeron adujeron que eran demasiado largas. Así, estas declaraciones se consideran demasiados complejas y poco claras (Luxemburgo 52%, Francia 47%, España 46%).
El Estado
A los riesgos provenientes del mundo privado se suman los no menos importantes vinculados al control gubernamental. En Estados Unidos, ya en el año 2000, la Comisión Federal de Comercio había recomendado al Congreso que se regulara la privacy online[72]. A pesar de esto, después de los ataques del 11 de septiembre de 2001 contra las Torres Gemelas en Nueva York, la atención general se centró en el tema de la seguridad, dejando la privacidad en un segundo plano. Por otro lado, la economía digital ha continuado captando paulatinamente el interés de los gobiernos, sobre todo porque entendieron que detrás de este sector se escondía la posibilidad de disponer de un mayor acceso a los datos y, por lo tanto, un mayor control sobre las personas. La recogida masiva y el análisis de datos personales ha fortalecido a los gobiernos, que, hoy en día, probablemente saben más que nunca sobre sus ciudadanos.
De hecho, Laura Poitras, directora de la película documental Citizenfour, que recrea el escándalo de espías reportado por Snowden, en una entrevista con The Washington Post en 2014 declaró que “Facebook es un regalo para las agencias de inteligencia”[73]. El tipo de información que se ofrece actualmente otorga a los gobiernos la capacidad de anticipar protestas e, incluso, arrestar preventivamente a las personas que piensan que tomarán parte en estas.
En la misma línea, durante los últimos 20 años, el gobierno estadounidense ha activado un programa de vigilancia electrónica operado por la Agencia de Seguridad Nacional con el cual recaban datos a través de Google, Facebook y otras empresas de tecnología[74]. Este programa, llamado ‘PRISM’, se utiliza para rastrear búsquedas online, contenidos de correos, o conversaciones entre usuarios. Las plataformas han negado que colaboren con él, y han reiterado que la información que ofrecen al gobierno está siempre bajo el respeto a la ley y la privacidad de las personas[75].
Sin embargo, como veremos más adelante, hoy la gran amenaza para el derecho de los ciudadanos a la privacidad proviene de la unión entre Big State y Big Corporation. Por un lado, las plataformas digitales tienen una penetración que les permite reunir una gran cantidad de información; por otro, el Estado ostenta potencialmente la autoridad para acceder a estos datos. Por esta razón, es urgente pensar en una solución que no esté orientada simplemente a regular estas plataformas, sino también a reducir su poder; poder que, en un análisis final, puede transferirse a las autoridades en detrimento de los individuos.
‘Notice and Consent’, Paternalismo y ‘Nudging’
Frente a esta imagen tan poco alentadora, vale la pena centrarse en la posible salida. Hasta hace poco, el enfoque sobre la privacidad más utilizado era el anglosajón, caracterizado por tratar de empoderar en la medida de lo posible al usuario individual, a fin de evitar un intervencionismo exagerado y salvaguardar la libertad de las personas; este modelo se define típicamente como ‘notice and consent’, observar y consentir. En la práctica, en lo que podríamos llamar autogestión de la privacidad, se basaba en consultar a los usuarios qué tipo de recopilación de datos deseaban, garantizando el derecho de elección y que esta transferencia fuera segura gracias a tecnologías y procedimientos adecuados. El objetivo que perseguía este enfoque consistía en aumentar la alfabetización de los usuarios en términos de privacidad. A pesar de la noble intención, hay varias razones que han llevado a su replanteamiento. En primer lugar, el hecho de que los datos se almacenen hoy en día tras el uso de cualquier servicio online ha motivado que sea humanamente imposible ejercer un proceso continuo de toma de decisiones racionales para consentir su procesamiento. Además, el que haya cada vez más pop-ups que nos advierten de cualquier problema de privacidad se percibe como un obstáculo que hay que superar con el fin de obtener un servicio. A esto hay que añadir que el permiso o prohibición debe darse siempre en tiempo real, lo que dificulta la reflexión y aumenta el riesgo de que el aviso sobre la privacidad sea ignorado.
Por último, no ayuda a mejorar la situación que el tipo de preguntas formuladas a los consumidores resulte a menudo demasiado complejo, o emplee una jerga extremadamente técnica. Los estudios académicos muestran que la información proporcionada a los usuarios es demasiado voluminosa e intrincada para que estos la lean, entiendan y tomen decisiones que reflejen sus valores, preferencias e intereses[76]. Si los internautas se relacionaran con solo unas pocas realidades, ese enfoque seguiría siendo concebible, pero en un mundo donde tienen docenas de aplicaciones en sus teléfonos y están constantemente conectados con otros dispositivos, en casa y en el trabajo, pensar que se puede llevar a cabo este trabajo de alfabetización no es realista. Muy a menudo, los usuarios confirman el pop-up sin leer, con la esperanza de que nada grave sucederá. Todo ello invita a descartar el enfoque de ‘notice and consent’.
En el otro extremo, encontramos un enfoque paternalista, que tiene como objetivo limitar significativamente la capacidad de las empresas a la hora de recopilar los datos de los usuarios. También presenta algunos inconvenientes importantes, como no reconocer la heterogeneidad de opiniones de los usuarios sobre el uso de sus datos. Frente a los que están particularmente preocupados por su privacidad, hay otros que están dispuestos a conceder información sobre sí mismos a cambio de servicios. Por tanto, una aproximación excesivamente paternalista conlleva el riesgo de borrar esta distinción y reducir así la libertad de acción de los consumidores.
El tercer enfoque posible es el del liberalismo paterno;asociado con el concepto de nudging, que desarrolló el premio Nobel de la Economía Richard Thaler[77]. Este concepto, aplicado al contexto de la privacidad y la protección de datos, se traduce concretamente en los ajustes de default (o predeterminados). Su ventaja está relacionada con el sesgo del statu quo, por el que, una vez se toma una determinada decisión, hay una preferencia exagerada por mantenerla. Por lo general, este sesgo se analiza respecto a la elección de los fondos de pensiones, pero recientemente se ha pensado aplicarlo también al contexto de la privacidad. Lo interesante para nuestro caso es que la mayoría de las plataformas digitales que recogen datos ofrecen por defecto las opciones de máxima divulgación por parte de los usuarios. Por tanto, una ley que obligara a estos recopiladores a establecer como opciones predeterminadas aquellas más conservadoras con la divulgación de información sensible, a menos que el usuario decida lo contrario, podría garantizar una mejor protección de la privacidad. Recientemente, un informe publicado por el Stigler Centre de la Universidad de Chicago sugería que, cuando las preferencias y expectativas de los consumidores (recogidas a través de estudios científicos) coincidan con las prácticas de las empresas, estas opciones deberían adoptarse por defecto. Sin embargo, cuando las preferencias y expectativas de los consumidores difieran de las de las empresas, resultaría más apropiado utilizar las opciones de los consumidores como regla de default, dejando espacio para la flexibilidad en caso de que las compañías fueron capaces de convencer a aquellos sobre las bondades de su propuesta[78]. Nos extenderemos en el capítulo 4 sobre la coherencia de este planteamiento con lo que ha adelantado la reforma del RGPD. Así, su propuesta parece compatible, por un lado, con la diversidad de preferencias de los usuarios, y por otro, evita que, aprovechándose de esta, las plataformas digitales pueden manipularlos y empujarles a que tomen decisiones que amenacen su bienestar.
Queda por ver hasta qué punto la propuesta de nudging respeta los principios del liberalismo clásico, perspectiva desde la que este informe quiere contribuir al debate sobre plataformas digitales y privacidad. A este respecto, es importante, en primer lugar, subrayar la diferencia entre esta forma de liberalismo y otras fórmulas más extremas que se remontan al ‘anarco-liberalismo’, que, en su vertiente tecnológica, se ha definido como ‘cripto-liberalismo’[79].
Estos últimos temas abarcan puntos de vista bastante extremos, y probablemente idealistas, sobre el potencial de la tecnología para fortalecer la libertad. Por contra, el liberalismo clásico reconoce el valor y la utilidad de un marco regulatorio capaz de respetar la autonomía y facilitar las transacciones voluntarias y de beneficios entre individuos. De hecho, estas reglas están configuradas para proteger esa autonomía individual, indispensable para que las personas puedan elegir libremente[80].
Al desgranar los méritos de la propuesta de este informe, la idea de nudging, asociada con el paternalismo liberal, se basa en el hecho de que haya ‘expertos’ capaces de enmarcar opciones, de tal manera que las preferencias personales coincidan con lo que los usuarios ‘deberían’ elegir por su propio bien. Tradicionalmente, la idea de un grupo de expertos que elija en nombre del resto de la población choca con esos principios de autonomía específicos del liberalismo, por los cuales las personas, a través del ejercicio de su libertad y la posibilidad de cometer errores, crecen en responsabilidad y capacidad de progreso.
La crítica del mundo libertario acerca de la efectividad de estos ‘expertos’ es correcta, incluso corriendo el riesgo de olvidar otra dimensión también importante. Si podemos pensar que los ‘expertos’, aliasel gobierno, representan una amenaza para la libertad y la autonomía individual, también debemos tener en cuenta que, en el contexto de la privacy online, la elección del usuario nunca se produce de una manera totalmente neutral. A las sugerencias de los ‘expertos’, que pueden crear distorsiones, se opone una opción de ‘default’ diseñada por y para el beneficio exclusivo de las plataformas digitales (para que recopile la mayor cantidad de datos posible). En ese contexto, hay que evitar soluciones que se aferren a motivaciones ideológicas.
Por ello, la propuesta de reglas por defecto basadas en las preferencias de los consumidores es consistente con un liberalismo que no se cierra tout court a un conjunto de normas. En este caso, se recurriría a los ‘expertos’ para identificar científicamente las preferencias promedio de los usuarios, y sugerir opciones predeterminadas acordes con estos datos, y no con opiniones personales o institucionales (o razones de Estado no especificadas) . Además, hay que reiterar cómo esta propuesta no excluye a los usuarios dispuestos a compartir su información.
En este sentido, una legislación capaz
de defender la diversidad de preferencias, y por tanto de elección, de los
consumidores, y de evitar al mismo tiempo que las empresas que operan en el
sector digital se muevan sin ningún tipo de restricción, se trata de una buena solución,
coherente con una libertad individual y responsable.
CAPÍTULO IV. EL FUNCIONAMIENTO DEl RPDG
El Reglamento General de Protección de Datos (RPDG) es, sin duda, el proyecto de ley sobre privacidad y protección de datos más ambicioso en vigor. Se aplica en los países miembros de la UE desde mayo de 2018, y, poco a poco, se está convirtiendo también en una referencia para leyes similares en el resto del mundo. Por esta razón, analizarlo resulta indispensable para los fines de nuestro informe, que no realizará, sin embargo, un estudio detallado, sino que se limitará a destacar algunos aspectos relacionados con sus consecuencias sobre el usuario y las empresas.
El punto de partida es que el RPDG ha impuesto reglas estrictas para el procesamiento de datos por parte de las plataformas digitales, y ha creado derechos significativos para los usuarios. El Reglamento define como datos personales toda aquella información relacionada con una persona identificable o identificada —también denominada «interesada» (Art. 3)—, y prevé una mayor protección de aquella considerada sensible, incluyendo raza, estado de salud, orientación sexual y antecedentes penales. Su aplicación se extiende a todas las entidades registradas en la UE, incluidas las extranjeras que procesan datos personales de los residentes comunitarios, cuya actividad se refiere a la prestación de bienes y servicios, así como a la recopilación de datos destinados a rastrear comportamientos. Las autoridades nacionales a cargo, normalmente los distintos garantes de la privacy, ejercen una función de supervisión y, en caso de incumplimiento, pueden emitir multas de hasta el 4% de los ingresos totales de una empresa, o de 20 millones de euros, dependiendo de cuál de ambas cifras sea mayor. El RPDG también brinda a asociaciones comerciales y organizaciones sin ánimo de lucro la posibilidad de iniciar una class action que permite demandar a ciertas compañías por cuenta de los consumidores.
En cuanto a los sujetos dedicados al tratamiento de los datos, el RPDG introduce una diferencia entre los “data collectors” (los dueños del tratamiento) y los “data processors” (responsables del tratamiento) (Cap. 4 – Art. 24-43). Los primeros determinan la finalidad de la recopilación de datos y los medios para su tratamiento, mientras que los segundos, después de recibirlos, se ocupan de gestionarlos. Los propietarios están obligados, en general, a cumplir con una serie de deberes, que incluyen el de demostrar laconformidad,no solo de ellos mismos, sino también de los responsables, los cuales también han de supervisar el comportamiento, y revelar la existencia de cualesquiera terceras partes que gestionarán los datos de los consumidores. Son siempre los propietarios los que luego tienen que informar a estos de cómo se utilizarán aquellos, por cuánto tiempo se retendrán, y cómo se respetarán los derechos a ellos inherentes.
En lo que respecta a los fundamentos en los que se basa toda la estructura regulatoria, hemos de referirnos a dos principios (introducidos en el Art. 25): el de ‘privacy by design’ y ‘privacy by default’. El primero implica un enfoque conceptual que requiere que las empresas inicien un proyecto, proporcionando desde el comienzo la configuración correcta para proteger los datos personales, como el uso de seudónimos o la minimización de la información presente en la estructura de productos y servicios. Este principio gira, por un lado, alrededor de la idea de que los problemas deben abordarse en la fase de diseño para evitar que se produzcan riesgos, y por otro, en la centralidad de los derechos y de las respuestas claras y rápidas a las solicitudes de acceso.
Con el principio de ‘privacy by default’ se ha procurado, por el contrario, asegurar que, por defecto, las empresas tienen que tratar los datos personales solo en la medida en que se necesite para los fines fijados y durante el período estrictamente requerido. Esto permitiría al usuario recibir un alto nivel de protección, incluso sin esforzarse a la hora de limitar la recopilación de datos (por ejemplo, habilitando la opción ‘opt out’). En este sentido, podemos ver cómo estos principios son coherentes con el enfoque de nudging presentado en el capítulo 3. Su introducción, por otra parte, obliga a las empresas a preparar una evaluación del ‘impacto de la privacidad’ cada vez que se lanza un proyecto que prevé un tratamiento de datos. Esto no puede subestimarse, ya que genera una serie de costes para las empresas en el que nos detendremos más adelante.
Si bien el RPDG ha aumentado las obligaciones regulatorias para las compañías, también ha alumbrado una serie de derechos para los consumidores. Así, los interesados pueden solicitar que los propietarios y responsables faciliten una explicación del tipo de datos que están recopilando y cómo se utilizarán en el futuro, así como pedir que sus datos sean corregidos o eliminados. Aunque los titulares pueden compartir la información de los interesados con terceros para cumplir con el objetivo inicial del tratamiento, no pueden hacerlo con un fin diferente, a menos que el consumidor lo permita o el titular emplee una nueva base legal. Los datos personales pueden transferirse fuera de la UE, pero, en general, solo a aquellos países en los que la protección de la privacy esté en vigor de una forma equivalente (una decisión que depende de la Comisión Europea).
Por último, el RPDG exige a las empresas que apliquen ciertas prácticas de seguridad con los datos. Sus titulares, por ejemplo, deben dedicarse a la “minimización”, que consiste en recopilar únicamente aquellos necesarios para llevar a cabo una tarea determinada, y conservarla solo por el tiempo preciso para cumplir con la finalidad por la que se recogieron y trataron (a menos que se utilicen en interés público). Las empresas también han de implementar las medidas técnicas adecuadas que garanticen la seguridad o limiten el riesgo de una fuga o divulgación no autorizada de datos personales. Aunque no impone ninguna medida concreta, el RPDG recomienda (Art. 32) el uso de ciertas técnicas como la seudonimización y el cifrado de datos, o un proceso de verificación de la eficacia de estas medidas tecnológicas y organizativas[81].
Una vez realizado este análisis no exhaustivo de los aspectos técnicos introducidos por el RPDG, podemos resaltar algunos de los hallazgos hasta la fecha:
- El RPDG estandariza y fortalece los derechos de los ciudadanos en la recopilación y el tratamiento de datos personales, y al mismo tiempo, también refuerza el papel supervisor de las autoridades nacionales de protección de datos, dado que les brinda la oportunidad de controlar el respeto al marco de trabajo y multar cualquier incumplimiento.
- EL RPDG es definitivamente un paso adelante desde el punto de vista del respeto al consumidor. Los principios ‘by design’ y ‘by default’ obligan a los organismos públicos, las organizaciones y las empresas a cambiar la forma en que abordan la gestión de los datos personales, y a considerar la privacidad ya en el mismo diseño de un producto, impidiendo al mismo tiempo que se recopile más información de la necesaria. Este punto, ha representado una importante inversión en la arquitectura de las páginas web, a menudo estructuradas de tal manera que los usuarios revelarían el mayor número de datos personales posibles (dado el incentivo que las plataformas tienen para utilizarlos a través del ‘target advertising’ o mediante la venta a terceras empresas para la predicción del comportamiento).
- El RPDG ofrece nuevas posibilidades para que los usuarios administren sus datos y soliciten información sobre cuáles se almacenan y cómo se utilizan. Con la opción de descargar todos aquellos que una empresa tenga sobre él, un internauta puede controlar lo que retienen las plataformas y decidir si los exporta a otros servicios. Sin embargo, para que los datos personales sean tratados, hace falta el consentimiento de los usuarios, que han de ser informados de manera inequívoca sobre el fin perseguido. En comparación con la situación pasada, en la que el consentimiento del usuario resultaba mucho más genérico, el RPDG proporciona una delimitación específica de los diferentes propósitos, de tal manera que el este puede decidir otorgar su permiso en función del interés que tenga en cada momento. En este punto, corresponderá a los reguladores nacionales y a los tribunales dirimir cómo se interpretan las disposiciones sobre el consentimiento de los usuarios. De hecho, es posible que las plataformas digitales establezcan la demanda de datos de tal forma que incentiven a los consumidores para tomar la decisión que más les beneficia (patrones oscuros).
Si respecto a los consumidores hay varios aspectos que parecen positivos, también desde la perspectiva empresarial el RPDG nació con la intención de potenciar un desarrollo positivo del sector digital. El cumplimiento de las nuevas disposiciones podría mejorar la gestión de datos e inspirar nuevos modelos de negocio. En este sentido, una investigación global realizada por el IBM Institute for Business Value sobre ejecutivos de diferentes áreas industriales ha señalado que los gestores percibieron la nueva legislatura como una oportunidad para ganarse la confianza de los consumidores. Así, el respeto por el RPDG funcionaría como un elemento distintivo en un entorno competitivo, en particular mediante el fortalecimiento de la relación con los clientes[82].
Por otro lado, la implantación del RPDG ha comportado una inversión significativa en términos financieros y tecnológicos para las empresas. Cada una, independientemente de su tamaño, tuvo que incorporar software, soporte técnico y asesoramiento legal para garantizar el cumplimiento de la ley. Las nuevas disposiciones sobre el tratamiento de datos y los estrictos plazos para identificar cualquier problema de seguridad e informar a las autoridades han resultado particularmente costosos para las grandes compañías. Algunos estudios han revelado que la cantidad total gastada por los miembros de la lista Fortune 500 asciende a alrededor de 7.800 millones de dólares, entre inversión técnica, reclutamiento de expertos y formación del personal[83].
La necesidad de plantilla adicional sigue presentándose como uno de los aspectos más problemáticos de la nueva regulación. El RPDG dispone (Art. 37) que cada servicio que necesita de un seguimiento regular de las partes interesadas a gran escala está obligado a designar a un ‘data protection officer’ (DPO) —un oficial de protección de datos (Art. 37) —, el encargado del cumplimiento de las normas de tratamiento. La interpretación de lo que supone ‘a gran escala’ continúa siendo objeto de interpretación, y la última palabra le corresponde a la empresa. Dada esta incertidumbre, la mayoría de compañías podrían optar por contratar personal adicional como una especie de póliza de seguro contra el incumplimiento de las normas.
La posible confusión generada por el RPDG no afectaría solo a las grandes corporaciones o multinacionales. De hecho, el verdadero problema descansa en las pequeñas y medianas, para las cuales incluso un gasto extra modesto podría resultar decisivo. Por esta razón, los planes de negocio de las PYMES deben contemplar estos costes adicionales destinados a la formación de trabajadores, y la compra del software y hardware necesarios para cumplir con lo que se propone el RPDG.
Las pequeñas y medianas empresas también se enfrentan a un obstáculo más, vinculado a la ventaja indirecta que el RPDG ofrece a las grandes en términos de confianza del consumidor. Las compañías ya establecidas no solo tienen fondos que les permiten garantizar la compatibilidad con el RPDG, sino también un gran número de clientes que estarán dispuestos a otorgarles su consentimiento para compartir datos personales, dado que reconocen estas marcas y confían en ellas. Con el nuevo reglamento, las empresas más pequeñas y las start-ups encontrarían más dificultad, tanto en lo relativo a la inversión necesaria para el cumplimiento del RPDG, como para ganarse la confianza del consumidor a la hora de competir con rivales más grandes que dominan el mercado.
Nacido con la intención de defender a los consumidores contra políticas sobre privacidad particularmente agresivas de las plataformas digitales, el debate sobre la eficacia del RPDG sigue abierto. En cuanto, por ejemplo, a la cifra de multas elevadas impuestas por las autoridades nacionales a causa de violaciones del RPDG, la cuantía total es de más de 55 millones de euros, la mayoría procedentes de una de 50 millones de euros reclamada por el autor nacional francés (CNIL) a Google. Esta multa, la más alta por quebrantar el RPDG, cubrió las quejas presentadas en mayo de 2018 por la organización austriaca “None of Your Business” y la ONG francesa “La Quadrature du Net” por la creación de cuentas de Google durante la configuración de teléfonos móviles con sistema operativo Android[84].
Gráfico 2:
Elaboración de los autores sobre datos http://www.enforcementtracker.com/ (se han excluido las sanciones propuestas por el regulador de Reino Unido a British Airlines y Marriott, que, en conjunto, ascienden a más de 300 millones de euros. La razón de esta exclusión es que las sentencias aún no han concluido).
Con estas excepciones, la inmensa mayoría de estas penalizaciones han afectado a las pequeñas y medianas empresas. Esto es interesante porque, por un lado, parece confirmar que las pymes, que deberían haberse beneficiado de un mayor control sobre la gran tecnología, están pagando unos costes relativamente altos en términos de cumplimiento o sanciones, y por otro, sugiere que, algunas excepciones onerosas aparte, los grandes jugadores han encontrado una manera de alinearse con el nuevo reglamento (sobre todo, gracias a la posibilidad de permitirse más gastos para satisfacer los recursos legales). Con el ánimo de extraer algunas consideraciones finales, el panorama actual revela que la regulación del RPDG no ha garantizado una mayor competencia dentro del sector de las plataformas digitales, sino, más bien, asestar un golpe a nuevas realidades, consolidando la posición de los incumbents; en cuanto a la protección de la privacidad, los mayores riesgos parecen provenir de las empresas más grandes, como se ha visto en el capítulo 3. El hecho de que en su mayoría aún no hayan sido sancionadas por violaciones del RPDG indica que es poco probable que la regulación disuada de la mala conducta. Esta última hipótesis cobra fuerza si la referenciamos con la situación mundial. La relación entre los ingresos de las big tech y las sanciones de la Comisión Europea y la Comisión Federal de Comercio (Autoridad de Protección del Consumidor de los Estados Unidos), por razones no solo relacionadas con la privacidad, constituye una evidencia especialmente clara de lo poco probable que resulta que las empresas perciban estas penalizaciones como una amenaza.
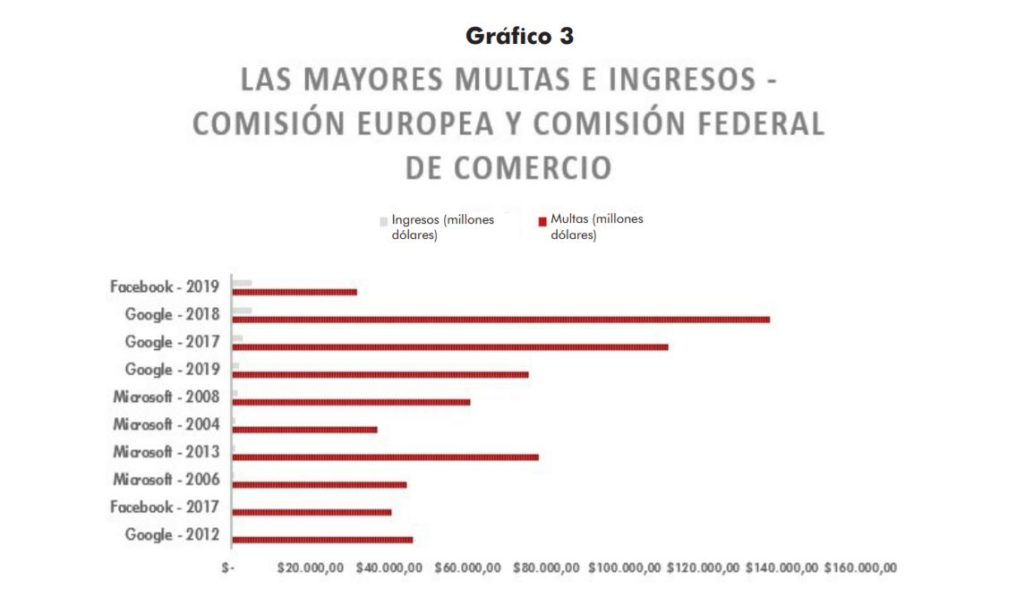
Las grandes multas y las amplias acciones de imposición han estado ausentes en gran medida, y, de hecho, durante este periodo, han surgido nuevas formas de recopilación de datos, incluida la reintroducción de la tecnología de Facebook de reconocimiento facial en Europa y los esfuerzos de Google para recabar información en sitios web de terceros[85].
Como podemos observar en la Figura 5, entre Google, Facebook y Microsoft (las Big Techs más sancionadas hasta hoy entre Comisión Europea y FTC), solo el social network ha recibido unas multas que se acercan casi al 10% de sus ingresos anuales: la multa de 5 billones de dólares que Facebook recibió en agosto de 2019 supone el 16% de las ganancias de los primeros seis meses de ese año.
A través este análisis, no defendemos unas políticas sancionadoras más duras, sino todo lo contrario: los castigos monetarios son casi inefectivos para neutralizar a estas empresas si no se acompañan de verdaderas acciones para incentivar la competencia.
CAPÍTULO V. POSIBLES SOLUCIONES FUTURAS
Ante esta falta de efecto dominó que muchos políticos y académicos esperaban después del RPDG, más voces se han levantado con nuevas propuestas para solucionar el descontrol dentro del mercado de los datos. Como en el capítulo 3, podemos distinguir entre quienes proponen una mayor regulación por parte de las instituciones públicas, y quienes consideran que la clave reside en dotar de mayor poder a las personas a la hora de elegir su posición respecto a cada plataforma.
Propuestas de regulación y antitrust
Las leyes antimonopolio se han configurado muchas veces como el método más eficiente para controlar a las grandes corporaciones y limitar su poder, ampliar la competición en el mercado y generar innovación. El propio Google ha conseguido su actual posición dominante gracias a los límites que las autoridades públicas americanas y europeas pusieron a Microsoft a finales de los años 90. Citando el profesor Luigi Zingales, “los monopolios de hoy son las start-ups de ayer”[86].
En líneas generales, hay tres ideas principales a favor de una mayor regulación antitrust de este mercado: separar los diferentes negocios de estas plataformas, restringir los mercados en los que puedan entrar, y hacer una revisión de las fusiones y adquisiciones dentro de estas empresas.
La propuesta más exitosa en el debate público es la separación estructural de las mayores plataformas, que tiene como defensora más ferviente a la senadora estadounidense Elizabeth Warren, quien aboga por una completa división de las empresas tecnológicas que tengan un ingreso anual superior a 25.000 millones de dólares, y por un control más estricto de aquellas que ingresen entre 90 y 25.000 millones de dólares[87]. Además, exige una legislación que prohíba a plataformas como Amazon ofrecer un mercado y participar en él. Esto implicaría, por tanto, que se separen las partes de los negocios que operan las plataformas de aquellas que venden y monetizan datos. En un artículo publicado recientemente, se demuestra cómo las disoluciones estructurales de mercados operados por pocos jugadores han supuesto un elemento fundamental de la regulación económica estadounidense, al impedir que los intermediarios del sector compitieran con las empresas que dependían de sus servicios[88]. El caso más emblemático se produjo dentro del sector de los ferrocarriles. En los primeros años del siglo XX, un pequeño grupo de empresas ferroviarias controlaban tanto las vías de transporte como el carbón y otros recursos. El Hepburn Act de 1906 obligó a separar las compañías de transportes de las que negociaban los recursos. La senadora Warren, y otros exponentes políticos, apuestan, pues, por esta misma división en el ámbito de las plataformas digitales. Y es que, una empresa como Amazon, que se utiliza como marketmaker, puede sacar ventajas vendiendo allí sus propios productos.
Sin embargo, esta postura ha recibido críticas por equiparar las plataformas digitales con otras compañías cuyo modelo de negocio es completamente distinto. La monetización de los datos forma parte intrínseca de la generación de ingresos de aquellas, y, por tanto, podría llevar a algunas a cobrar para participar del mercado.
La segunda idea semejante a la anterior contempla una revisión de las fusiones y adquisiciones dentro de las empresas tecnológicas. La respaldan dos objetivos principales: por un lado, fraccionar algunas fusiones que se han realizado en los últimos años. Estamos hablando de las adquisiciones de Instagram y WhatsApp por parte de Facebook, y de YouTube por la de Google. En ambos casos, se trata de compañías que podrían sobrevivir sin sus empresas matrices, así como competir por mejores oportunidades. Instagram y YouTube sobre todo tienen un modelo de negocio completamente independiente de Facebook y Google. Otro ejemplo podemos encontrarlo en PayPal y Ebay. El otro objetivo pasa por asegurar que empresas emergentes en el sector tecnológico tengan posibilidades de competir con las grandes plataformas sin ser englobadas dentro de las Big Tech.
La tercera propuesta tendente a una mayor regulación consiste en restringir a estas empresas la entrada en nuevos mercados, por ejemplo, el financiero. La limitación más peligrosa de esta propuesta se cifra en la perdida de la innovación que estas empresas se hallan en disposición de ofrecer a la sociedad. La enorme inversión que las Big Techs están haciendo en otros mercados a través de la inteligencia artificial podría revestir mucha importancia para la creación de nuevos negocios y mercados.
‘Pro-market’ y no ‘Pro-businesses’
Al mismo tiempo, varios estudios científicos han demostrado que la capacidad de adquisición por parte de grandes empresas en detrimento de las start-ups es una razón para que los capitales de riesgo tengan un menor interés en invertir en pequeñas compañías innovadoras, el verdadero elemento vital de una economía de mercado. En este sentido, la propuesta de limitar las grandes plataformas digitales (a través de la fragmentación, en lugar de con un mayor control sobre las fusiones y adquisiciones) presenta una profunda raíz liberal. Textos como Saving Capitalism from Capitalists de Rajan y Zingales, dos profesores de economía de la Universidad de Chicago, han reiterado que el peligro de los grandes monopolios reside en frenar la innovación, en producir barreras de entrada que reducen la competencia, y en aumentar los costes para el consumidor final. La necesidad de redimensionar la fuerza económica y política de estos gigantes de la web resulta coherente con aquellos que se sienten cercanos a una posición ‘pro mercado’, que no significa ‘pro businesses’[89]. Sobre esta diferencia, el mismo Adam Smith, en The Wealth of Nations, advirtió que los hombres de negocios, tratando de consolidar su posición hegemónica en el mercado, pueden acabar creando barreras de entrada y cárteles, o sea, verdaderos ‘Club Deals’ que no benefician a los consumidores[90].
Obviamente, esta situación la contrarresta una regulación que quiere trasladar todo el control a los gobiernos, nacionales o europeo. El hecho de que el propio Zuckerberg se haya mostrado a favor de una mayor normación por parte de las autoridades públicas[91] no puede dejarnos indiferentes. Las grandes Big Tech no temen demasiado este escenario porque, como se ha mencionado en el caso del RPDG, tienen recursos de compliance capaces de garantizarles una posición ventajosa en comparación con los nuevos competidores. Facebook, por ejemplo, se ha mostrado particularmente dispuesto a colaborar con las diversas autoridades, también en lo que respecta a la privacidad de los ciudadanos. Por otro lado, una estrecha cooperación entre Big Tech y Big Government (pensando, sobre todo, en que la gestión de este supuesto pasase a manos de la UE) es lo más distante de un enfoque liberal, dados los numerosos riesgos en términos de libertad de opinión, expresión y movimiento que produciría una alianza de este tipo. A pesar de estar fuera del tema central de este informe, un ejemplo concreto del peligro de esta unión entre el Leviatán estatal y los Behemoths digitales lo encontramos en la prohibición de Facebook, posteriormente eliminada, de patrocinar una publicación de una asociación irlandesa Pro-Life. La razón alegada fue que constituía, según la red social, un caso de discurso de odio[92]. Está claro que, en la medida en que las redes sociales han alcanzado tal nivel de omnipresencia en nuestra sociedad, las empresas privadas como Facebook estén comenzando a asumir más roles públicos (como determinar qué representa un discurso de odio y qué no). Pero que cualquier regulación de estos supuestos pueda ser el resultado de acuerdos entre la compañía digital individual y los gobiernos nacionales o supranacionales no se trata de un buen augurio en lo que a la libertad de los ciudadanos concierne.
Circunscribiéndonos a este último aspecto, vale la pena enfatizar que este riesgo no es una característica exclusiva de nuestros tiempos, sino algo intrínseco a todos los procesos tecnológicos. Estos, por un lado, aumentan las libertades individuales de las personas, pero, por otro, se erigen en arma poderosa para los gobiernos que, a través de las innovaciones, pueden ampliar su capacidad de control. Es por eso por lo que derechos como los de privacidad continúan siendo absolutamente centrales. Dado que nuestra sociedad se caracteriza por el binomio Estado-mercado, hay que pensar en instituciones socioeconómicas en las que las personas sean lo más centrales posible para evitar su aniquilación.
Distinto sería que la palabra clave en la regulación en los años venideros fuera ‘fragmentación’. Aunque esta suponga un duro golpe para los ingresos de las grandes plataformas digitales, podría promover una mayor competencia entre las empresas medianas y fomentar la innovación. Al igual que en todos los problemas complejos, no existe una solución de ‘atajo’, y tirar de la manta por un lado destapa el otro.
Entre los mayores críticos de la visión más intervencionista del mercado de datos se encuentra Tyler Cowen, autor del libro Big Business: A Love Letter to an American Anti-Hero, en el cual defiende a las corporaciones y su papel esencial en nuestra sociedad como promotoras del progreso. El autor, hablando de Alphabet, recuerda los beneficios que la matriz de Google ha traído, en forma de servicios eficientes y novedosos. Pensemos en Android, que Google compró en 2005 y que convirtió en uno de los softwares para móviles más utilizado en el mundo. “Debido a la combinación Google-Android, cientos de millones de personas han disfrutado de teléfonos inteligentes mejores y más baratos. En términos más generales, Google ha hecho que la mayor parte de su software sea de código abierto, lo que permite a otros desarrollarlo con avances adicionales, con empresas enteras dedicadas ahora a ayudar a otras a construir sobre esa infraestructura”[93]. Por no hablar de YouTube, que Google adquirió por 1,65 mil millones de dólares, y que actualizó y libró de los problemas legales que estaba sufriendo por violar repetidamente los derechos de autor.
A través de estos dos ejemplos, se pueden entrever las dificultades existentes a la hora de regular las plataformas digitales. Está claro que un mayor control sobre estas empresas, ya sea restringiendo sus mercados o fraccionándolas, llevaría a un coste de oportunidad para la sociedad que no todos desean. Lo que no obsta para que los defensores[94] más fervientes del libre mercado opinen que se necesita cierta intervención para defender la privacidad de las personas.
El ‘Data as Labor’
En esta tesitura, en la que no parece haber otra solución que recibir servicios “gratuitos” a cambio de facilitar más datos a las empresas tecnológicas, algunos investigadores han ofrecido una opción realmente revolucionaria, enfocando el problema desde otro prisma. El punto de partida de Eric Posner y Glen Weyl, respectivamente profesor de Derecho en la Universidad de Chicago e investigador en Microsoft, es que el mercado de los datos se ha vuelto un mercado de trueque [95]. Además, dado que los datos presentan rendimientos crecientes y que, gracias a la inteligencia artificial, cada uno de ellos es útil para mejorar un servicio, todas las plataformas digitales están interesadas en recibir la mayor información posible de los usuarios. Sin embargo, la falta de incentivos de cara a proporcionar información suplementaria hace que este mercado no resulte completamente eficiente. Posner y Weyl ponen un ejemplo para explicarlo: cuando un usuario sube una foto a una plataforma como Facebook, la red social está interesada en obtener más detalles sobre ella, como el lugar donde se tomó, si es un recuerdo bonito, si los demás usuarios están presentes en la foto, etc… Todo ello permitiría a Facebook mejorar su servicio, y sin embargo, lo pierde por no ofrecer algo a cambio. Con esta simple ilustración nace el concepto de Data Labor, una visión distinta del mercado de los datos que permite a individuos y plataformas obtener lo que necesitan. La idea consiste en que estas paguen a aquellos para acopiar más información. A través de este método, los datos pasan de ser un factor de capital a uno de trabajo. En la tabla figuran las distintas características que los datos tienen en función de que se los considere de una forma u otra.
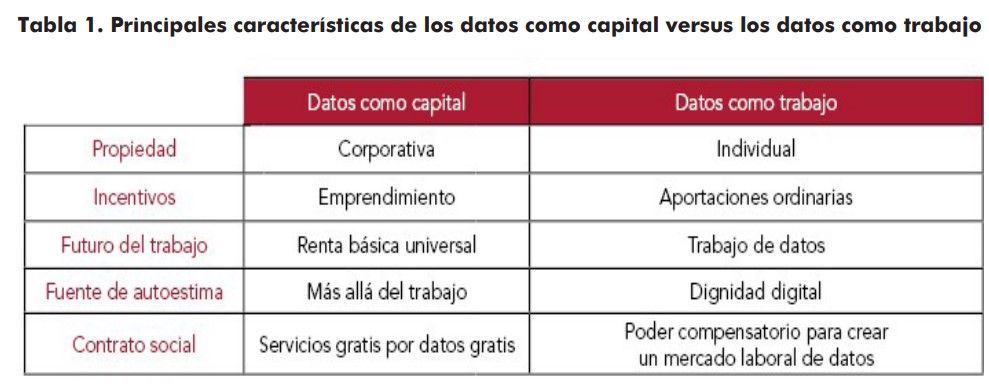
Sin entrar en detalle en todos los asuntos de la tabla, para lo cual remitimos al artículo “Should we treat data as Labor?”, sí hay dos ideas que merecen particular atención respecto al tratamiento de los datos como factor de trabajo. La primera es la fuerza que se les da a los usuarios. Dejan de ser sujetos pasivos y se convierten en protagonistas del mercado de datos. La propiedad pasa a sus manos, ya que tienen el poder de ofrecer su información a las plataformas que ellos prefieran y defender así su privacidad. Como ya hemos visto en los capítulos anteriores, la propiedad de los datos resulta fundamental para un buen funcionamiento de este mercado. La segunda idea se refiere a la colaboración que se puede crear entre usuarios y plataformas. En virtud de esta visión, las personas adquieren mayor relevancia de cara a que las empresas ofrezcan más posibilidades en el mercado. Por otra parte, las plataformas podrán pedir más datos a cambio de dinero y, por tanto, crear más oportunidades a través de la inteligencia artificial. Según Posner y Weyl, esta propuesta acrecentaría la economía digital y lograría distribuir algunos beneficios desde las plataformas a los trabajadores. Pero incluso esta descripción binaria de “Data as Labor” y “Data as Capital” resulta demasiado limitada. Probablemente, los datos sean algo intermedio, dada su heterogeneidad. En cualquier caso, incentivar a los usuarios reportaría muchos beneficios, al responsabilizarlos y aclarar su papel. Además, podrían unirse en sindicatos y acumular mayor poder de negociación frente a las Big Tech[96]. El sindicato se hallaría en disposición de pedir a sus miembros que boicotearan las plataformas un día entero, bloqueando completamente el sistema. Según Posner y Weyl, “durante una huelga, la plataforma perdería acceso a los datos (por el lado del trabajo) y a las ganancias de las publicidades (por el lado del consumidor)”. Asimismo, “un sindicato de datos podría ayudar a fomentar la competencia digital al romper el dominio de los datos de algunas de las compañías más poderosas”[97].
Hay otra diferencia importante entre las propuestas anteriores y la que se acaba de presentar: la regulación y la división de las plataformas limitaría en muchos aspectos este mercado pero también a las personas. El “data as labor” confiere importancia a estas, y un rol fundamental en el futuro de la inteligencia artificial. De hecho, investiría de una nueva dignidad al trabajo, y no haría falta una renta universal, muchas veces propuesta como compensación a las pérdidas laborales por causa de la automatización. Los datos son trabajo que las personas ofrecen a las empresas. Así, los usuarios se sentirían parte de la cadena de valor que está detrás de ellas.
Los autores no excluyen la necesidad de una intervención por parte de las autoridades para defenderse del riesgo de monopolio por parte de las grandes plataformas. De hecho, para que los datos sean realmente propiedad de los usuarios se necesita una regulación fuerte que los proteja, como intenta hacer de alguna manera el RPDG.
Esta transformación, cultural antes que tecnológica, según la cual los datos pasarían a constituir un factor de trabajo en lugar de uno de capital, resulta muy consistente con un enfoque liberal que quiera poner a la persona en el centro de los procesos económicos y sociales.
CAPÍTULO VI. CONCLUSIONES
Al principio de este informe, recordábamos que el World Economic Forum ha bautizado a este periodo histórico como ‘web of the world’, la web del mundo, donde las personas están conectadas en una misma red a través de las nuevas tecnologías. Sucesivamente, hemos visto que la clave para esta interconexión descansa muchas veces en las plataformas digitales, empresas que nacen como marketplace para unir demandas y ofertas de bienes y servicios, recogiendo a cambio los datos de los usuarios, centro del modelo de negocio de este mercado. Hemos visto también que este no es un mercado como los demás, ya que tiene tres aspectos significativos que lo diferencian: los rendimientos de escala creciente, los efectos network y el ciclo virtuoso que se crea a través de la inteligencia artificial. Estos tres atributos, y en especial el último, permiten a las plataformas dominantes crecer exponencialmente y tener cada vez más control del mercado. En los últimos veinte años, las empresas tecnológicas, y en concreto Google, Facebook, Amazon, Microsoft y Apple, se han transformado en las compañías más grandes del mundo, cotizando valores nunca vistos.
Frente a su crecimiento y la novedad del mercado de los datos, muchas autoridades públicas han empezado a discutir sobre determinados riesgos relacionados con las Big Tech: el de un monopolio que limita la futura innovación y un mercado competitivo; el que pesa sobre nuestra democracia, dado que algunas de estas plataformas se han convertido en intermediarios entre las autoridades y los usuarios; y el de la falta de privacidad, que se traduce en una mayor posibilidad de que gobiernos y empresas conozcan aspectos sensibles de la vida de la personas. Además, este intercambio de datos personales no siempre se produce con el consentimiento y la comprensión real por parte de los usuarios, lo que incrementa la amenaza para su libertad.
Este informe ha querido hacer hincapié en este último punto, dada su importancia para la privacidad y que los ciudadanos vivan en una sociedad libre. Frente a un debate público que cada día se ve enriquecido con más noticias sobre abusos por parte de gobiernos y empresas, se han analizado las principales propuestas que se están elaborando sobre este tema. Por un lado, como enfoque más utilizado en el pasado más reciente, está el ‘notice and consent’, que pretende garantizar la máxima libertad a las personas para que gestionen su privacidad con cada plataforma según sus propios gustos. Esta propuesta, aunque alentadora, no toma en consideración la complejidad del sistema actual y la manera en que las plataformas se pueden aprovechar para obtener más datos. En el otro extremo, hay aproximaciones demasiado paternalistas, que quieren limitar la capacidad de las plataformas y así reducir la diversidad de preferencias. Por último, el tercer enfoque posible es el del liberalismo paterno, asociado, en particular, con el concepto de nudging, el cual, en lo relativo a la protección de datos, se encarna en los ajustes de default. Esta solución requiere que las opciones predeterminadas respecto a la privacidad estén diseñadas de tal forma que la información más personal no se comparta automáticamente. Existe un debate sobre quién debe determinar cuándo y cuál debe protegerse mediante este mecanismo. Aunque parece constituir un justo punto medio entre libertad individual y control sobre las empresas, algunos críticos más libertarios discuten sobre la eficacia de los ‘expertos’ que tomarían determinadas decisiones sobre las preferencias de los individuos. Por otro lado, el hecho de que estas se adoptaran, no de acuerdo a opiniones personales o institucionales, sino como resultado de estudios científicos diseñados para obtener el promedio de las preferencias de los usuarios, hace que esta solución pueda considerarse compatible con el respeto a la libertad individual y una mayor capacidad de elección por parte de los consumidores.
Respecto a esta propuesta, el RPDG de la Unión Europea intenta defender mejor la privacidad de los individuos dándoles más control sobre sus informaciones y, de hecho, el principio de ‘privacy by default’ está en la base de todo el Reglamento. Nacido con la intención de proteger a los consumidores contra políticas sobre privacidad particularmente agresivas de las plataformas digitales, a lo largo del informe, se ha podido verificar también que el RPDG ha creado muchos problemas en el mercado de los datos. Las empresas han tenido que soportar unos costes de compliance tan altos que muchas pequeñas y medias no han conseguido cubrir todos los aspectos de la nueva regulación. De hecho, comparando las sanciones impuestas por las autoridades competentes sobre este asunto, se constata que, a excepción del caso contra Google promovido por la autoridad francesa, casi todas se han dirigido contra pequeñas empresas. Esto demuestra que, aunque el RPDG ha concedido más derechos a los consumidores, no ha logrado crear un mercado más competitivo. Más bien todo lo contrario: las pequeñas compañías sufren las sanciones europeas, mientras las Big Tech gastan en compliance y mantienen así su posición dominante, ensanchando las divergencias con las demás plataformas. El informe también subraya que la alianza que se está generando entre Big Tech y Big Government no puede dejar indiferente, dado que puede comprometer seriamente la libertad del individuo. Esto se restringiría con los mecanismos de control de la autoridad pública, por un lado, y los intentos de capturar información por parte de las empresas, por el otro. Sea como sea, es urgente una regulación que ponga el respeto a la libertad de las personas en el centro y esto pasa por una mayor competencia entre las plataformas digitales.
Esta impotencia del RPDG a la hora de limitar el riesgo de monopolio de las grandes empresas tecnológicas lleva a preguntarse qué otras propuestas hay en el mundo académico y político para defender este mercado tan joven y ya tan importante para nuestra sociedad. La recomendación más está en línea con los principios del liberalismo clásico es el concepto de ‘Data as Labor’. Las razones son varias, y el punto principal estriba en la dignidad que se le da a la persona. Dada la revolución tecnológica que caracteriza la era actual, el “futuro del trabajo” se convierte en un asunto extremadamente delicado. Como consecuencia de una hipotética automatización de muchos trabajos, han surgido múltiples propuestas para favorecer un ingreso básico universal. Pasar de tratar los datos como factor de capital a uno de trabajo resolvería en parte este problema. A través de este modelo, no toda la información se ofrecería gratuitamente, por lo que gran parte de ella se transformaría en ingresos para los usuarios. Este cambio permitiría también que las personas fueran las dueñas de los datos, y no empresas o gobiernos. Esta nueva propiedad solventaría dos aspectos importantes: por un lado, la privacidad, dado que los individuos poseerían sus propios datos y podrían proporcionarlos a quienes quisieran, y por el otro, el riesgo de monopolio. Las personas decidirían por sí mismas a quién dar sus datos y a quién quitarlos, facilitando así la migración de información de una plataforma a otra y haciendo más flexible el ‘efecto network’. Por tanto, se brindaría a las pequeñas empresas, con nuevas ideas, más posibilidades de tener éxito en el mercado, y no solo la de dejarse comprar por los grandes operadores[98].
Es innegable que esta propuesta plantea todavía muchas incógnitas a las que sus defensores tiene que contestar. Sin embargo, parece un paso importante hacia un mercado de datos más competitivo y que dé más protagonismo a las personas. Hasta la fecha, ha habido varias iniciativas que están intentando poner en marcha este concepto[99].
En conclusión, pensamos que un ‘web of the world’ necesita ‘data workers’.
BOX I: Las Big Tech sobrepasan a los bancos
Como podemos ver en las figuras 2 y 3, en solo quince años las principales plataformas digitales han crecido exponencialmente, con una capitalización de mercado mucho mayor que los bancos globales más significativos. En el análisis propuesto, hemos seleccionado los bancos y las tecnológicas [100]más grandes por capitalización de mercado en Europa y Estados Unidos en 2005 y 2019.
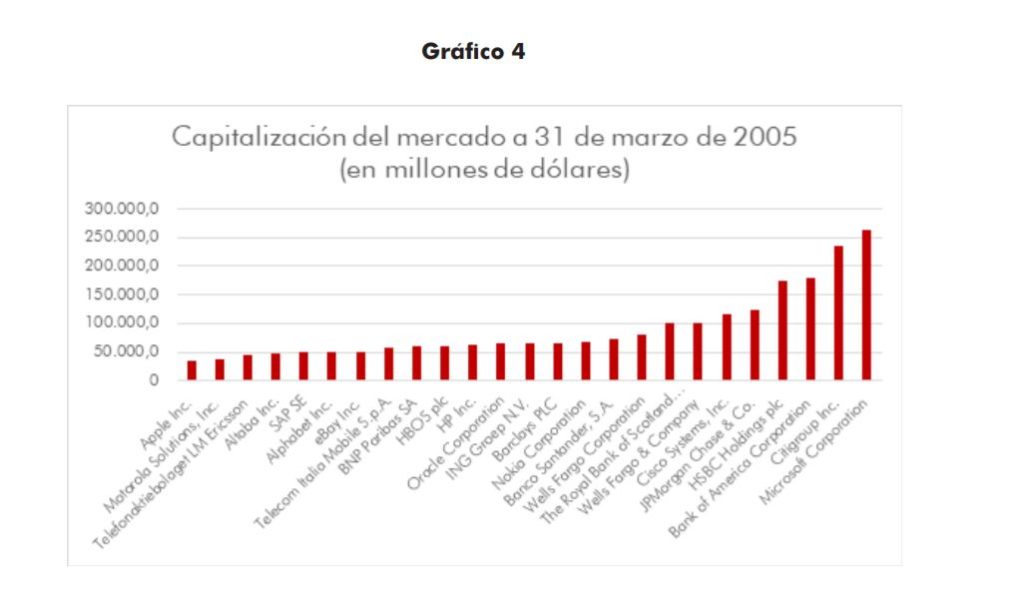
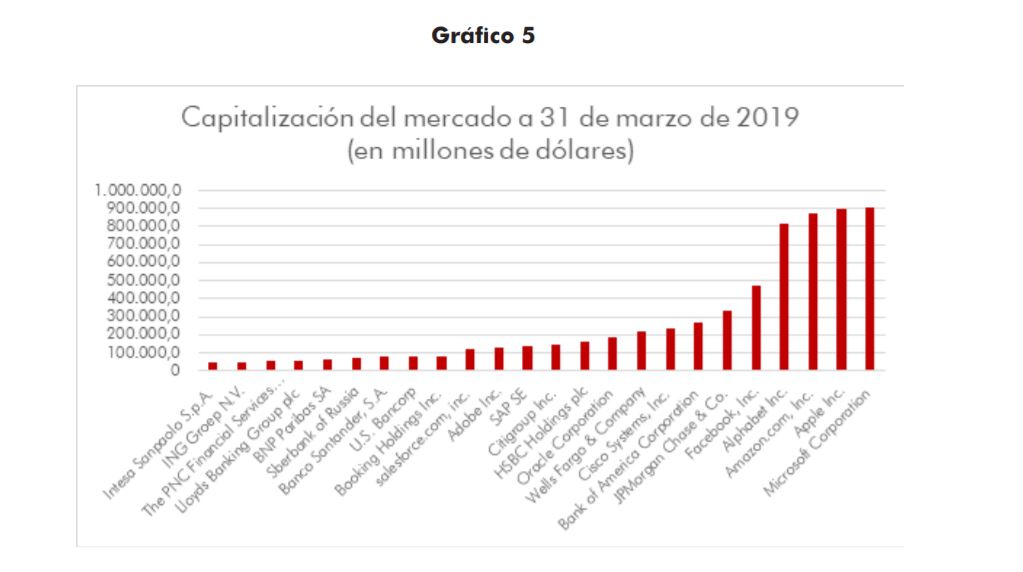
Como se puede ver, en 2005, solo Microsoft estaba por encima de los principales bancos americanos y europeos. Apple, Amazon y Alphabet se hallaban muy por debajo de la capitalización de las instituciones financieras. Quince años después, la imagen es completamente distinta: las empresas tecnológicas han crecido a niveles altísimos en comparación con el sistema bancario. No en vano, en ese periodo, Facebook ha conseguido situarse entre las empresas más cotizadas del mundo.
BOX II: Cambridge Analytica
Cambridge Analytica (CA) ha sido el suceso más emblemático que el análisis de datos haya podido deparar en nuestra democracia. Sin entrar en cuestiones ideológicas, este caso resulta particularmente interesante por la posibilidad de que algo similar ocurra en el futuro. CA era una empresa que combinaba la minería de datos y su análisis con la comunicación estratégica para procesos electorales. Trabajó para campañas importantes, como la de Mauricio Macri, actual presidente de Argentina, y la de Donald Trump en su candidatura a la Casa Blanca. En muchas de ellas, aunque se hizo más patente en el caso estadounidense, la empresa se vio involucrada en el escándalo de haber influido en elecciones políticas utilizando para ello datos de usuarios, lo que iba en contra de las normas de Facebook.
Entre 2013 y 2015, CA recopiló datos de los perfiles de 50 millones de usuarios de esta red social sin su permiso, y los usó para crear una base de marketing masiva basada en los gustos e intereses individuales de cada usuario. La información se obtuvo gracias a una aplicación desarrollada por el académico británico Aleksandr Kogan. Unas 270.000 personas la descargaron e iniciaron sesión con sus credenciales de Facebook. La app reunía sus datos y los de sus amigos, y luego Kogan se los pasaba a CA. Esta información estaba permitida por la rede social, y como reiteró uno de sus portavoces al New York Times, “no se infiltraron sistemas, y no se robaron ni piratearon contraseñas, ni información confidencial”.[101] Lo único que estipulaba Facebook, y que violó CA, fue vender y comercializar estos datos a otras compañías. Luego, se utilizaron para construir modelos “psicográficos”[102], con los que se influyó en los votantes estadounidenses.
La situación se agravó cuando, en marzo 2018, Facebook reconoció que a finales de 2015 ya había descubierto que la información se había recogido a una escala sin precedentes. Sin embargo, en ese momento, no alertó a los usuarios, y solo tomó medidas limitadas para recuperar y proteger la información privada de más de 50 millones de personas, pidiendo a CA que la eliminara[103].
En 2018, tres años después de lo sucedido, a través de una publicación en Facebook, Zuckerberg anunció otras medidas encaminadas a proteger los datos de los usuarios en Facebook, y admitía, después de que lo hubieran destapado las investigaciones de “The Guardian”, del “The New York Times” y de Channel 4, que era posible que Cambridge Analytica no hubiera borrado los datos de los usuarios[104]. Las revelaciones sobre Facebook y CA han provocado una gran reacción pública y una reevaluación del poder que el gigante de las redes sociales ha acumulado. Sin duda, pensar que Facebook pueda proteger nuestros datos parece una ingenuidad y un riesgo para nuestra democracia.
[1] World Economic Forum. Personal Data: The emergence of a new asset class. 2011, p. 5.
[2] European Commission. Online Platforms.https://ec.europa.eu/digital-single-market/en/online-platforms-digital-single-market
[3] European Commission. Competition policy for the digital era. 2019, p. 12.
[4] World Economic Forum. Personal Data. Op.cit.
[5] Judit Duportail. I asked Tinder for my data. It sent me 800 pages of my deepest, darkest secrets. The Guardian. 26 Sept. 2017
[6] Luigi Zingales y Guy Rolnik, A Way to Own Your Social-Media Data. The New York Times. 30 Jun. 2017.
[7] European Commission. Competition policy. Op. cit. p.25.
[8] La diferencia entre el machine learning y una técnica de
programación tradicional es que mientras en la técnica clásica el ordenador
necesita los datos y el programa para sacar por unos resultados, en el machine
learning, el ordenador necesita los datos y los resultados para darte el
programa. Una vez tienes el programa, puedes utilizarlo para sacar más
información o para encontrar unos nuevos resultados.
Arthur Samuel. Field
of study that gives computers the ability to earn without being explicitly
programmed. 1959
Para una comprensión más exhaustiva del machine learning, aconsejamos la
visualización de esta clase introductoria del machine learning por parte del
profesor del MIT, Eric Grimson: Introduction to Machine Learning.
https://www.youtube.com/watch?v=h0e2HAPTGF4:
[9] Bradford De Long y Michael Froomkin. The Next Economy?. Internet Publishing and Beyond: The Economics of Digital Information and Intellecutal Property. MIT Press, Cambridge, Massachusetts (1998).
[10] Facebook news: https://newsroom.fb.com/company-info/
[11] Eric Posner y Glen Weyl. Radical Markets. Princeton University Press. 2018, p. 209.
[12] Stigler Center. Market Structure and Antitrust Subcommittee. 2019, p.16.
[13] European Commission. Competition policy. Op. cit. 2019, p.23.
[14] Glen Weyl y Alexander White. Let the Right one Win: Policy Lessons from the new economics of Platforms. 2014. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2524368
[15] Tarlenton Gillespie. The Politics of Platforms. New Media & Society 12(3). 2010. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1601487
[16] Weyl y White. Let the Right one Win. Op. cit.
[17] Edmond de Rothschild. How is Big Data changing our lives?. 2017. https://www.youtube.com/watch?v=2FUNmc49GTU
[18] European Commission. Competition policy. Op. cit.
[19] Eric Posner y Glen Weyl. Radical Markets. Princeton University Press. 2018, p. 214.
[20] Posner y Weyl. Radical Market. Op.cit. p. 214.
[21] Bobbie Johnson, Privacy no longer a social norm, says Facebook founder. The Guardian. 10 Ene. 2010. https://www.theguardian.com/technology/2010/jan/11/facebook-privacy
[22] Sara Salinas y Anita Balakrishnan, Mark Zuckerberg has been talking and apologizing about privacy since 2003. CNBC. 18 Dic. 2018
[23] Lina Khan. The Separation of Platforms and Commerce. Columbia Law Review 2019, p. 5.
[24] Rana Foroohar. Big Tech is America’s new ‘railroad problem’. Financial Times, 16 Jun. 2019.
[25] Lina Khan. The Separation of Platforms and Commerce. Columbia Law Review 2019.
[26] Jeff Disjardins. How the Tech Giants Make Their Billions. Visual Capitalist. 29 Mar. 2019.
[27] eMarketers. Google and Facebook Tighten Grip on US Digital Ad Market. 21 Sept. 2017
[28] Megan Graham. Amazon is turning advertising into its next huge business — here’s how. CNBC. 17 July 2019: https://www.cnbc.com/2019/07/17/how-amazon-advertising-works.html
[29] Facebook for business: https://www.facebook.com/business/success/2-blenders-eyewear
[30] Google Search (Shopping): Antitrust Procedure. European Commission. 26 Jun. 2017. P.10/11
[31] Facebook para empresas: https://www.facebook.com/business/help/675615482516035?helpref=faq_content
[32] What Is Google AdWords? How the AdWords Auction Works: https://www.wordstream.com/articles/what-is-google-adwords
[33] How to Use Facebook Lookalike Audiences: https://www.wordstream.com/facebook-lookalike-audiences
[34] 2019 ANTITRUST AND COMPETITION CONFERENCE, Pt 10: «Privacy and Data Protection: The Broader Debate», Stigler Center: https://www.youtube.com/watch?v=0TA4jC0bxX0&t=14s
[35] P&G Puts Ad Platforms Like Facebook, Google on Notice. Bloomberg. 11 April 2019
[36] Michael Zammuto. Why Google and Amazon can win in any business – including yours. CIO. 5 Jun. 2018
[37] Julia Boorstin. A lesson plan from tech giants on how to transform education. CNBC. 28 Mar. 2017
[38] Nancy Huynh. How the “Big 4” Tech Companies Are Leading Healthcare Innovation. Healthcare Weekly. 27 Febr. 2019
[39] Bank for International Settlement. Big tech in finance: opportunities and risks. 23 Jun. 2019
[40] World Economic Forum. The New Physics of Financial Services. Ago. 2018
[41] Con respeto al mercado de seguros, las big techs están distribuyendo productos de seguros pero todavía es un mercado pequeño en comparación con los préstamos y los pagos.
[42] Bank for International Settlement. Big tech in finance: opportunities and risks. 23 Jun. 2019 p. 3
[43] World Economic Forum. The New Physics of Financial Services. Ago. 2018
[44] Amazon Go: https://www.amazon.com/b?ie=UTF8&node=16008589011
[45] Libra: https://libra.org/es-LA/
[46] Arjun Kharpal. Everything you need to know about WeChat — China’s billion-user messaging app. CNBC. 3 Febr. 2019.
[47] Para una comprensión más exhaustiva del blockchain: https://www.blockchaintechnologies.com/blockchain-technology/
[48] Informe de la Libra: https://libra.org/es-LA/white-paper/
[49] Libra website: https://libra.org/es-LA/partners/
[50] Hannah Murphy. What is Libra, Facebook’s new digital coin? Financial Times. 18 Jun. 2019.
[51] Joint statement on global privacy expectations of the Libra network. 2 Ago 2019. https://ico.org.uk/media/about-the-ico/documents/2615521/libra-network-joint-statement-20190802.pdf
[52] Hannah Murphy. What is Libra, Facebook’s new digital coin? Financial Times. 18 Jun. 2019.
[53] Facebok ha negado este punto dado que no crearía dinero, si no que lo utilizaría solo como reserva para que su moneda sea estable.
[54] Open Banking: https://www.openbanking.org.uk/customers/what-is-open-banking/
[55] PSD2: https://www.ecb.europa.eu/paym/intro/mip-online/2018/html/1803_revisedpsd.en.html
[56] Nicholas Megaw. Santander and eBay to launch loans app in UK. Financial Times. 3 Jun. 2019.
[57] Radical Market, Posner y Weyl, p. 220
[58] Bobbie Johnson, Facebook privacy change angers campaigners. The Guardian. 10 Dic. 2009. https://www.theguardian.com/technology/2009/dec/10/facebook-privacy
[59] Dina Srinivasan. The Antitrust Case Against Facebook. Berkley Business Law Journal. Vol. 16 (1). Una. 2019.
[60] David Kirkpatrick, The Facebook Effect: The Inside Story of the Company That Is Connecting the World. Simon & Schuster. 2011.
[61] Wendy E. Mackay, Triggers and Barriers to Customizing Software.Conf. On human factors in
Computing sys. 153-160. 1991.
[62] John Schwartz, Giving Web a Memory Cost Its Users Privacy. New York Times. 4 Sept. 2001.
[63] Srinivasan. The Antitrust case. Op. cit.
[64] Arvind Narayanan y Vitaly Shmatikov. Robust De-anonymization of large datasets (How to break anonymity of the Netflix Prize Dataset). University of Texas Austin.
[65] Michael Kearns y Aaron Roth. The Ethical Algorithm. 2019. Oxford University Press.
[66] Luc Rocher, Julien M. Hendrickx y Yves-Alexandre de Montjoye. Estimating the success of re-identifications in incomplete datasets using generating models. Nature Communications. 10(3069). 2019
[67] Natalia Drozdiak y Giles Turner. Los gigantes tecnológicos arriesgan sondas de privacidad sobre Alexa, revisores de Siri. Bloomberg. Ago 6 2019. https://www.bloomberg.com/news/articles/2019-08-05/tech-giants-risk-privacy-probes-over-alexa-siri-eavesdropping
[68] Privacy International. Alexa, stop being creepy! https://privacyinternational.org/feature/2820/alexa-stop-being-creepy-our-letter-jeff-bezos
[69] Arunesh Mathur et al.,Dark patterns at scale: findings from a crawl of 11k shopping websites, Working Paper. https://webtransparency.cs.princeton.edu/dark-patterns/assets/dark-patterns.pdf
[70] Paul Hitlin y Lee Rainie, Facebook Algorithms and Personal Data, Centro de Investigación Pew. 2019.
[71] Eurobarómetro especial 431, Protección de datos. 2015
[72] Federal Trade Commission. Privacy Online: Fair Information Practices in the Electronic Marketplace: A Federal Trade Commission Report to Congress. 2000 https://www.ftc.gov/reports/privacy-online-fair-information-practices-electronic-marketplace-federal-trade-commission
[73] Andrea Peterson. Snowden filmmaker Laura Poitras: ‘Facebook is a gift to intelligence agencies’. 2014. https://www.washingtonpost.com/news/the-switch/wp/2014/10/23/snowden-filmmaker-laura-poitras-facebook-is-a-gift-to-intelligence-agencies/
[74] Glenn
Greenwald and Ewen MacAskill. NSA Prism program taps in to user data of
Apple, Google and others. The Guardian 2013.
https://www.theguardian.com/world/2013/jun/06/us-tech-giants-nsa-data
[75] Frederic
Lardinois. Google, Facebook, Dropbox, Yahoo, Microsoft, Paltalk, AOL And Apple
Deny Participation In NSA PRISM Surveillance Program. June 7, 2013
https://techcrunch.com/2013/06/06/google-facebook-apple-deny-participation-in-nsa-prism-program/?guccounter=1&guce_referrer_us=aHR0cHM6Ly9lcy53aWtpcGVkaWEub3JnLw&guce_referrer_cs=4WcyH2GiWZ0ukxEthDxx4w
[76] Yannis Bakos, Marotta-Wurgler F. y Trossen, D. R. Does Anyone Read the Fine Print? Consumer Attention to Standard Form Contracts. La Revista de Estudios Jurídicos, 43(1), 1-35. 2014
[77] Richard Thaler y Cass R. Sunstein. El paternalismo libertario no es un oxímoron. Journal of legal studies, 1159-1202. 2003.
[78] Centro Stigler, Privacy and Data Protection. 2019, p.29.
[79] Justin Hurwitz y Geoffrey A. Manne, Classical liberalism and the problem of technological change. White Paper. International Center for Law and Economics. 2018-1.
[80] Richard A. Epstein, Let “the fundamental things apply”: Necessary and contingent truths in legal scholarship, 115 Harvard Law Review 1300, 1302. 2002
[81] https://www.boe.es/doue/2016/119/L00001-00088.pdf
[82] Ibm Instituto de Valor Empresarial, The end of the beginning, Executive Report. 2018. https://www.ibm.com/downloads/cas/JEMXN6LV
[83] Mehereen Khan, ‘Companies face high cost to meet new EU data protection rules’, Financial Times, Nov. 2017. https://goo.gl/UxLP33
[84] The CNIL’s restricted committee imposes a financial penalty of 50 Million euros against GOOGLE LLC. 2019. https://www.cnil.fr/en/cnils-restricted-committee-imposes-financial-penalty-50-million-euros-against-google-llc
[85] Google/RPDG: not as advertised. Financial Times. 04 April 2019
[86] Line of Inquiry: Luigi Zingales on how today’s monopolies are yesterday’s startups. Chicago Booth Review. 11 May 2017
[87] Astead Herndon. Elizabeth Warren Proposes Breaking Up Tech Giants Like Amazon and Facebook. The New York Times. 8 March 2019
[88] Lina Khan. The separation of platforms and commerce. Columbia Law Review. 2019
[89] Luigi Zingales. Capitalism after the crisis. National Affairs. Fall 2009. https://nationalaffairs.com/publications/detail/capitalism-after-the-crisis
[90] Adam Smith, The Wealth of Nations, “People of the same trade seldom meet together, even for merriment and diversion, but the conversation ends in a conspiracy against the public, or in some contrivance to raise prices.” (Smith 1950: 82).
[91] Come scrisse lo stesso Zuckemberg in seguito al suo incontro con il presidente francesce Macron: “We both believe governments should take a more active role around important issues like balancing expression and safety, privacy and data portability, and preventing election interference — reflecting their own traditions of free speech. (…) This is our first official collaboration on regulation with a government, and we’re hopeful this process could work for other countries..” n
[92]Harry Brent. Zuckerberg says Facebook banned pro-life ads during Irish abortion vote. 11 Jul. 2019. https://www.irishpost.com/news/mark-zuckerberg-says-facebook-banned-pro-life-ads-irish-abortion-vote-168902
[94] Tyler Cowen. Breaking up Big Tech would be a big mistake.
The Globe and Mail. 17 April 2019:
“There are genuine privacy concerns that apply to Facebook, Google and other
major tech companies. Those are problems worth addressing, including through
the law
[95] Posner y Weyl. Radical Market. 2018
[96] The Data Union: https://thedataunion.eu/
[97] Posner y Weyl. Radical Market. 2018. Page 242-243
[98] Sin embargo, no se puede negar que sobre todo al principio las grandes empresas seguirían teniendo ventaja gracias a los rendimientos de escala crecientes y a los ciclos virtuosos del IA. Por tanto, muchas start-ups necesitarán colaborar con las big tech para tener un espacio en el mercado. No obstante, la situación sería más flexible que ahora
[99] Implementations of Data as Labor: http://radicalmarkets.com/chapters/data-as-labor/implementations/
[100] Hemos considerado empresa tecnológica cualquiera que esté definida por Capital IQ en la misma industria de Amazon, Alphabet, Apple, Facebook y Microsoft
[101] How Trump Consultants Exploited the Facebook Data of Millions. The New York Times. March 17, 2018: https://www.nytimes.com/2018/03/17/us/politics/cambridge-analytica-trump-campaign.html
[102] La segmentación psicográfica trata de proporcionar a las empresas un perfil del consumidor que les sirva para aumentar las ventas de sus productos, fidelizar a los clientes e incrementar el prestigio de sus marcas. Los rasgos psicográficos hacen referencia a la personalidad, estilo de vida, intereses, aficiones y valores de los consumidores. Gracias a la segmentación psicográfica las compañías pueden dividir el mercado en grupos basados en características de personalidad.
[103] Facebook acknowledges concerns over Cambridge Analytica emerged
earlier than reported. The Guardian. March 22, 2019:
https://www.theguardian.com/uk-news/2019/mar/21/facebook-knew-of-cambridge-analytica-data-misuse-earlier-than-reported-court-filing
[104] Marc Zuckerberg, Facebook’s profile: https://www.facebook.com/zuck/posts/10104712037900071
Bibliografía
• Personal Data: The Emergence of a New Asset Class. WEF, 2011
• Competition policy for the digital era. European Commission, 2019
• Market Structure and Antitrust Subcommittee. Stigler Center, 2019
• Radical Markets. Posner and Weyl 2018
• The New Physics of Financial Services. WEF, 2018
• Unpopular privacy: What must we hide. Anita Allen, 2011
• Libertarian Paternalism. Thaler, Richard, H., y Cass R. Sunstein. 2003. American Economic Review, 93 (2): 175-179.
• Privacy in the modern age: The search for solutions. Marc Rotenberg, 2015
• Should we treat Data as Labor? Weyl et al. 2017
• Big Business: A Love Letter to an American Anti-Hero. Tyler Cowen, 2019


